Q710E8
Gene name |
ORC1A |
Protein name |
Origin of replication complex subunit 1A |
Names |
AtORC1a, Origin recognition complex subunit 1a |
Species |
Arabidopsis thaliana (Mouse-ear cress) |
KEGG Pathway |
ath:AT4G14700 |
EC number |
|
Protein Class |
|
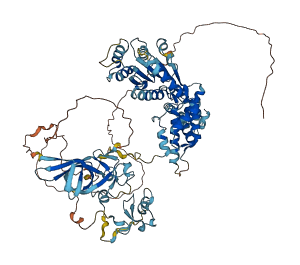
Descriptions
The autoinhibited protein was predicted that may have potential autoinhibitory elements via cis-regPred.
Autoinhibitory domains (AIDs)
Target domain |
|
Relief mechanism |
|
Assay |
cis-regPred |
Accessory elements
No accessory elements
Autoinhibited structure

Activated structure
1 structures for Q710E8
| Entry ID | Method | Resolution | Chain | Position | Source |
|---|---|---|---|---|---|
| AF-Q710E8-F1 | Predicted | AlphaFoldDB |
194 variants for Q710E8
| Variant ID(s) | Position | Change | Description | Diseaes Association | Provenance |
|---|---|---|---|---|---|
| tmp_4_8422242_T_G | 3 | S>A | No | 1000Genomes | |
| ENSVATH00504666 | 5 | L>P | No | 1000Genomes | |
| ENSVATH06665541 | 7 | S>A | No | 1000Genomes | |
| tmp_4_8422266_A_G | 11 | T>A | No | 1000Genomes | |
| tmp_4_8422275_T_G | 14 | S>A | No | 1000Genomes | |
| ENSVATH06665542 | 14 | S>F | No | 1000Genomes | |
| tmp_4_8422288_C_A | 18 | T>N | No | 1000Genomes | |
| ENSVATH11738232 | 21 | K>N | No | 1000Genomes | |
| ENSVATH14192944 | 26 | S>* | No | 1000Genomes | |
| tmp_4_8422317_C_A | 28 | L>I | No | 1000Genomes | |
| tmp_4_8422335_T_A | 34 | S>T | No | 1000Genomes | |
| ENSVATH02833654 | 37 | P>H | No | 1000Genomes | |
| ENSVATH11738235 | 40 | T>P | No | 1000Genomes | |
| tmp_4_8422368_A_G | 45 | T>A | No | 1000Genomes | |
| ENSVATH06665544 | 46 | P>S | No | 1000Genomes | |
| ENSVATH02833656 | 61 | G>E | No | 1000Genomes | |
| ENSVATH02833656 | 61 | G>V | No | 1000Genomes | |
| tmp_4_8422429_T_A | 65 | I>N | No | 1000Genomes | |
| tmp_4_8422432_A_T | 66 | D>V | No | 1000Genomes | |
| ENSVATH02833657 | 67 | L>F | No | 1000Genomes | |
| ENSVATH02833658 | 69 | G>E | No | 1000Genomes | |
| ENSVATH02833659 | 70 | K>R | No | 1000Genomes | |
| ENSVATH00504668 | 73 | V>I | No | 1000Genomes | |
| tmp_4_8422460_A_T | 75 | E>D | No | 1000Genomes | |
| ENSVATH11738236 | 77 | N>K | No | 1000Genomes | |
| ENSVATH06665549 | 82 | P>A | No | 1000Genomes | |
| ENSVATH06665550 | 82 | P>R | No | 1000Genomes | |
| ENSVATH06665553 | 91 | V>I | No | 1000Genomes | |
| ENSVATH06665554 | 95 | S>L | No | 1000Genomes | |
| tmp_4_8422518_T_C | 95 | S>P | No | 1000Genomes | |
| ENSVATH11738237 | 103 | E>Q | No | 1000Genomes | |
| ENSVATH06665555 | 105 | S>F | No | 1000Genomes | |
| tmp_4_8422572_C_T | 113 | R>* | No | 1000Genomes | |
| tmp_4_8422597_A_C,G | 121 | K>R | No | 1000Genomes | |
| tmp_4_8422597_A_C,G | 121 | K>T | No | 1000Genomes | |
| ENSVATH06665556 | 129 | K>N | No | 1000Genomes | |
| ENSVATH11738275 | 135 | T>A | No | 1000Genomes | |
| ENSVATH06665559 | 151 | A>P | No | 1000Genomes | |
| ENSVATH11738278 | 157 | E>D | No | 1000Genomes | |
| tmp_4_8422704_G_A | 157 | E>K | No | 1000Genomes | |
| ENSVATH06665560 | 161 | P>L | No | 1000Genomes | |
| ENSVATH11738280 | 166 | C>Y | No | 1000Genomes | |
| ENSVATH14192967 | 169 | C>S | No | 1000Genomes | |
| tmp_4_8422745_C_G | 170 | F>L | No | 1000Genomes | |
| ENSVATH06665561 | 171 | K>R | No | 1000Genomes | |
| ENSVATH06665562 | 173 | H>D | No | 1000Genomes | |
| tmp_4_8422755_A_G | 174 | T>A | No | 1000Genomes | |
| ENSVATH11738281 | 176 | T>A | No | 1000Genomes | |
| tmp_4_8422789_T_C | 185 | L>S | No | 1000Genomes | |
| ENSVATH06665563 | 190 | L>M | No | 1000Genomes | |
| ENSVATH02833660 | 190 | L>S | No | 1000Genomes | |
| ENSVATH11738282 | 194 | K>E | No | 1000Genomes | |
| ENSVATH06665566 | 212 | V>I | No | 1000Genomes | |
| tmp_4_8422878_T_C | 215 | S>P | No | 1000Genomes | |
| ENSVATH02833663 | 223 | P>S | No | 1000Genomes | |
| tmp_4_8422933_G_A | 233 | R>K | No | 1000Genomes | |
| ENSVATH14192968 | 234 | T>P | No | 1000Genomes | |
| tmp_4_8422942_A_G | 236 | K>R | No | 1000Genomes | |
| tmp_4_8422959_A_G | 242 | S>G | No | 1000Genomes | |
| ENSVATH06665570 | 259 | G>D | No | 1000Genomes | |
| tmp_4_8423038_A_G | 268 | Y>C | No | 1000Genomes | |
| ENSVATH00504670 | 275 | V>I | No | 1000Genomes | |
| tmp_4_8423064_G_A | 277 | G>R | No | 1000Genomes | |
| ENSVATH06665571 | 278 | R>I | No | 1000Genomes | |
| ENSVATH06665571 | 278 | R>T | No | 1000Genomes | |
| tmp_4_8423073_C_T | 280 | R>C | No | 1000Genomes | |
| tmp_4_8423108_T_A | 291 | N>K | No | 1000Genomes | |
| tmp_4_8423126_G_T | 297 | E>D | No | 1000Genomes | |
| ENSVATH08340362 | 301 | V>F | No | 1000Genomes | |
| ENSVATH06665576 | 302 | L>V | No | 1000Genomes | |
| ENSVATH06665577 | 309 | C>S | No | 1000Genomes | |
| ENSVATH11738306 | 314 | S>* | No | 1000Genomes | |
| ENSVATH06665580 | 317 | S>I | No | 1000Genomes | |
| ENSVATH14192969 | 336 | S>R | No | 1000Genomes | |
| ENSVATH06665583 | 338 | K>R | No | 1000Genomes | |
| ENSVATH06665585 | 340 | V>E | No | 1000Genomes | |
| ENSVATH06665584 | 340 | V>L | No | 1000Genomes | |
| ENSVATH06665586 | 342 | E>G | No | 1000Genomes | |
| ENSVATH06665587 | 347 | D>E | No | 1000Genomes | |
| ENSVATH02833668 | 347 | D>G | No | 1000Genomes | |
| ENSVATH06665589 | 352 | Q>L | No | 1000Genomes | |
| tmp_4_8423297_G_A | 354 | W>* | No | 1000Genomes | |
| tmp_4_8423301_G_T | 356 | G>C | No | 1000Genomes | |
| tmp_4_8423314_A_G | 360 | E>G | No | 1000Genomes | |
| ENSVATH06665590 | 362 | I>T | No | 1000Genomes | |
| ENSVATH06665591 | 364 | Y>D | No | 1000Genomes | |
| tmp_4_8423334_G_C | 367 | E>Q | No | 1000Genomes | |
| ENSVATH06665592 | 369 | I>F | No | 1000Genomes | |
| ENSVATH06665593 | 369 | I>M | No | 1000Genomes | |
| ENSVATH06665592 | 369 | I>V | No | 1000Genomes | |
| ENSVATH06665594 | 372 | D>G | No | 1000Genomes | |
| tmp_4_8423392_G_A | 386 | G>D | No | 1000Genomes | |
| ENSVATH14192971 | 390 | S>F | No | 1000Genomes | |
| tmp_4_8423407_G_T | 391 | R>L | No | 1000Genomes | |
| ENSVATH11738308 | 394 | R>C | No | 1000Genomes | |
| ENSVATH06665595 | 397 | G>R | No | 1000Genomes | |
| ENSVATH06665597 | 401 | V>M | No | 1000Genomes | |
| tmp_4_8423439_G_C | 402 | G>R | No | 1000Genomes | |
| tmp_4_8423462_T_A | 409 | H>Q | No | 1000Genomes | |
| tmp_4_8423487_T_A | 418 | L>I | No | 1000Genomes | |
| ENSVATH11738309 | 422 | K>T | No | 1000Genomes | |
| tmp_4_8423521_C_T | 429 | T>I | No | 1000Genomes | |
| tmp_4_8423541_TGTA_T | 436 | C>* | No | 1000Genomes | |
| tmp_4_8423554_A_G | 440 | E>G | No | 1000Genomes | |
| ENSVATH11738310 | 455 | D>Y | No | 1000Genomes | |
| ENSVATH11738311 | 456 | Q>* | No | 1000Genomes | |
| ENSVATH02833672 | 456 | Q>H | No | 1000Genomes | |
| ENSVATH06665600 | 457 | C>F | No | 1000Genomes | |
| ENSVATH06665600 | 457 | C>Y | No | 1000Genomes | |
| tmp_4_8423610_G_A | 459 | G>S | No | 1000Genomes | |
| tmp_4_8423621_G_A | 462 | M>I | No | 1000Genomes | |
| ENSVATH06665601 | 464 | I>M | No | 1000Genomes | |
| tmp_4_8423626_T_A | 464 | I>N | No | 1000Genomes | |
| ENSVATH06665602 | 465 | H>Y | No | 1000Genomes | |
| ENSVATH14192973 | 469 | G>D | No | 1000Genomes | |
| ENSVATH11738312 | 470 | T>P | No | 1000Genomes | |
| ENSVATH06665603 | 474 | I>N | No | 1000Genomes | |
| tmp_4_8423688_G_A | 485 | A>T | No | 1000Genomes | |
| ENSVATH11738313 | 485 | A>V | No | 1000Genomes | |
| ENSVATH14192974 | 506 | A>V | No | 1000Genomes | |
| tmp_4_8423765_C_A | 510 | N>K | No | 1000Genomes | |
| tmp_4_8423775_G_A | 514 | V>I | No | 1000Genomes | |
| ENSVATH02833676 | 516 | Y>C | No | 1000Genomes | |
| ENSVATH02833676 | 516 | Y>F | No | 1000Genomes | |
| ENSVATH06665605 | 523 | R>C | No | 1000Genomes | |
| tmp_4_8423809_G_A | 525 | G>D | No | 1000Genomes | |
| ENSVATH06665607 | 527 | K>N | No | 1000Genomes | |
| ENSVATH06665606 | 527 | K>T | No | 1000Genomes | |
| ENSVATH15004522 | 532 | S>F | No | 1000Genomes | |
| ENSVATH06665608 | 537 | F>S | No | 1000Genomes | |
| tmp_4_8423859_A_G | 542 | K>E | No | 1000Genomes | |
| tmp_4_8423860_A_G | 542 | K>R | No | 1000Genomes | |
| tmp_4_8423884_C_T | 550 | P>L | No | 1000Genomes | |
| ENSVATH02833677 | 552 | I>L | No | 1000Genomes | |
| ENSVATH06665610 | 552 | I>M | No | 1000Genomes | |
| ENSVATH11738314 | 555 | I>T | No | 1000Genomes | |
| ENSVATH14192976 | 556 | D>N | No | 1000Genomes | |
| ENSVATH08340370 | 568 | V>L | No | 1000Genomes | |
| ENSVATH00504674 | 571 | N>K | No | 1000Genomes | |
| ENSVATH11738395 | 583 | L>F | No | 1000Genomes | |
| ENSVATH00504675 | 585 | V>A | No | 1000Genomes | |
| tmp_4_8423988_G_C | 585 | V>L | No | 1000Genomes | |
| ENSVATH11738396 | 601 | R>Q | No | 1000Genomes | |
| tmp_4_8424059_A_G | 608 | I>M | No | 1000Genomes | |
| ENSVATH06665612 | 614 | G>S | No | 1000Genomes | |
| tmp_4_8424082_A_G | 616 | Y>C | No | 1000Genomes | |
| ENSVATH06665614 | 627 | T>I | No | 1000Genomes | |
| ENSVATH14192978 | 629 | L>F | No | 1000Genomes | |
| ENSVATH14192977 | 629 | L>W | No | 1000Genomes | |
| ENSVATH00504676 | 630 | E>K | No | 1000Genomes | |
| tmp_4_8424130_T_C | 632 | I>T | No | 1000Genomes | |
| ENSVATH14192979 | 638 | T>A | No | 1000Genomes | |
| tmp_4_8424156_G_A | 641 | E>K | No | 1000Genomes | |
| tmp_4_8424173_A_T | 646 | K>N | No | 1000Genomes | |
| tmp_4_8424196_CA_GA,C | 654 | A>G | No | 1000Genomes | |
| tmp_4_8424202_G_A | 656 | R>H | No | 1000Genomes | |
| ENSVATH02833681 | 657 | A>T | No | 1000Genomes | |
| tmp_4_8424220_G_A | 662 | R>K | No | 1000Genomes | |
| tmp_4_8424223_G_T,A | 663 | R>H | No | 1000Genomes | |
| tmp_4_8424223_G_T,A | 663 | R>L | No | 1000Genomes | |
| ENSVATH06665617 | 675 | S>I | No | 1000Genomes | |
| ENSVATH02833682 | 682 | Q>* | No | 1000Genomes | |
| ENSVATH06665618 | 692 | A>G | No | 1000Genomes | |
| tmp_4_8424313_T_A | 693 | I>N | No | 1000Genomes | |
| ENSVATH06665619 | 701 | H>Y | No | 1000Genomes | |
| tmp_4_8424345_G_A | 704 | V>I | No | 1000Genomes | |
| tmp_4_8424351_A_G | 706 | K>E | No | 1000Genomes | |
| ENSVATH00504678 | 712 | S>N | No | 1000Genomes | |
| tmp_4_8424379_T_A | 715 | F>Y | No | 1000Genomes | |
| tmp_4_8424390_A_G | 719 | M>V | No | 1000Genomes | |
| ENSVATH06665620 | 721 | H>Y | No | 1000Genomes | |
| tmp_4_8424415_G_C | 727 | G>A | No | 1000Genomes | |
| tmp_4_8424424_A_C | 730 | E>A | No | 1000Genomes | |
| tmp_4_8424423_G_A | 730 | E>K | No | 1000Genomes | |
| ENSVATH08340375 | 736 | V>I | No | 1000Genomes | |
| ENSVATH06665624 | 741 | S>L | No | 1000Genomes | |
| ENSVATH11738397 | 745 | L>* | No | 1000Genomes | |
| ENSVATH11738398 | 750 | A>T | No | 1000Genomes | |
| ENSVATH11738399 | 758 | L>P | No | 1000Genomes | |
| tmp_4_8424520_G_A | 762 | C>Y | No | 1000Genomes | |
| tmp_4_8424540_A_C | 769 | I>L | No | 1000Genomes | |
| ENSVATH06665625 | 774 | P>T | No | 1000Genomes | |
| ENSVATH06665626 | 778 | H>Y | No | 1000Genomes | |
| tmp_4_8424575_G_T | 780 | L>F | No | 1000Genomes | |
| ENSVATH06665627 | 786 | N>D | No | 1000Genomes | |
| tmp_4_8424598_C_G | 788 | P>R | No | 1000Genomes | |
| tmp_4_8424622_T_A | 796 | L>* | No | 1000Genomes | |
| tmp_4_8424629_C_A | 798 | D>E | No | 1000Genomes | |
| tmp_4_8424639_CTTCCATGG_ATTCCATGG,C | 802 | L>I | No | 1000Genomes | |
| tmp_4_8424646_G_A | 804 | W>* | No | 1000Genomes | |
| tmp_4_8424652_C_G | 806 | A>G | No | 1000Genomes | |
| ENSVATH11738400 | 807 | N>S | No | 1000Genomes | |
| ENSVATH00504679 | 809 | L>F | No | 1000Genomes | |
| ENSVATH04326403 | 810 | L>Y | No | 1000Genomes |
No associated diseases with Q710E8
7 regional properties for Q710E8
| Type | Name | Position | InterPro Accession |
|---|---|---|---|
| domain | Bromo adjacent homology (BAH) domain | 135 - 341 | IPR001025 |
| domain | Zinc finger, PHD-type | 165 - 211 | IPR001965 |
| domain | AAA+ ATPase domain | 458 - 612 | IPR003593 |
| domain | ATPase, AAA-type, core | 462 - 608 | IPR003959 |
| conserved_site | Zinc finger, PHD-type, conserved site | 166 - 210 | IPR019786 |
| domain | Zinc finger, PHD-finger | 163 - 213 | IPR019787 |
| domain | AAA lid domain | 636 - 675 | IPR041083 |
2 GO annotations of cellular component
| Name | Definition |
|---|---|
| nuclear origin of replication recognition complex | A multisubunit complex that is located at the replication origins of a chromosome in the nucleus. |
| origin recognition complex | A multisubunit complex that is located at the replication origins of a chromosome. |
6 GO annotations of molecular function
| Name | Definition |
|---|---|
| ATP binding | Binding to ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| ATP hydrolysis activity | Catalysis of the reaction: ATP + H2O = ADP + H+ phosphate. ATP hydrolysis is used in some reactions as an energy source, for example to catalyze a reaction or drive transport against a concentration gradient. |
| chromatin binding | Binding to chromatin, the network of fibers of DNA, protein, and sometimes RNA, that make up the chromosomes of the eukaryotic nucleus during interphase. |
| DNA replication origin binding | Binding to a DNA replication origin, a unique DNA sequence of a replicon at which DNA replication is initiated and proceeds bidirectionally or unidirectionally. |
| double-stranded methylated DNA binding | Binding to double-stranded methylated DNA. Methylation of cytosine or adenine in DNA is an important mechanism for establishing stable heritable epigenetic marks. |
| metal ion binding | Binding to a metal ion. |
4 GO annotations of biological process
| Name | Definition |
|---|---|
| DNA replication | The cellular metabolic process in which a cell duplicates one or more molecules of DNA. DNA replication begins when specific sequences, known as origins of replication, are recognized and bound by initiation proteins, and ends when the original DNA molecule has been completely duplicated and the copies topologically separated. The unit of replication usually corresponds to the genome of the cell, an organelle, or a virus. The template for replication can either be an existing DNA molecule or RNA. |
| DNA replication initiation | The process in which DNA-dependent DNA replication is started; this begins with the ATP dependent loading of an initiator complex onto the DNA, this is followed by DNA melting and helicase activity. In bacteria, the gene products that enable the helicase activity are loaded after the initial melting and in archaea and eukaryotes, the gene products that enable the helicase activity are inactive when they are loaded and subsequently activate. |
| mitotic DNA replication checkpoint signaling | A signal transduction process that contributes to a mitotic DNA replication checkpoint. |
| regulation of DNA-templated transcription | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
7 homologous proteins in AiPD
| UniProt AC | Gene Name | Protein Name | Species | Evidence Code |
|---|---|---|---|---|
| P54784 | ORC1 | Origin recognition complex subunit 1 | Saccharomyces cerevisiae (strain ATCC 204508 / S288c) (Baker's yeast) | PR |
| Q58DC8 | ORC1 | Origin recognition complex subunit 1 | Bos taurus (Bovine) | PR |
| O16810 | Orc1 | Origin recognition complex subunit 1 | Drosophila melanogaster (Fruit fly) | EV |
| Q13415 | ORC1 | Origin recognition complex subunit 1 | Homo sapiens (Human) | PR |
| Q9Z1N2 | Orc1 | Origin recognition complex subunit 1 | Mus musculus (Mouse) | PR |
| Q80Z32 | Orc1 | Origin recognition complex subunit 1 | Rattus norvegicus (Rat) | PR |
| Q9SU24 | ORC1B | Origin of replication complex subunit 1B | Arabidopsis thaliana (Mouse-ear cress) | PR |
| 10 | 20 | 30 | 40 | 50 | 60 |
| MASSLSSKAK | TFKSPTKTPT | KMYRKSYLSP | SSTSLTPPQT | PETLTPLRRS | SRHVSRKINL |
| 70 | 80 | 90 | 100 | 110 | 120 |
| GNDPIDLPGK | ESVEEINLIR | KPRKRTNDIV | VAEKSKKKKI | DPEVSFSPVS | PIRSETKKTK |
| 130 | 140 | 150 | 160 | 170 | 180 |
| KKKRVYYNKV | EFDETEFEIG | DDVYVKRTED | ANPDEEEEED | PEIEDCQICF | KSHTNTIMIE |
| 190 | 200 | 210 | 220 | 230 | 240 |
| CDDCLGGFHL | NCLKPPLKEV | PEGDWICQFC | EVKKSGQTLV | VVPKPPEGKK | LARTMKEKLL |
| 250 | 260 | 270 | 280 | 290 | 300 |
| SSDLWAARIE | KLWKEVDDGV | YWIRARWYMI | PEETVLGRQR | HNLKRELYLT | NDFADIEMEC |
| 310 | 320 | 330 | 340 | 350 | 360 |
| VLRHCFVKCP | KEFSKASNDG | DDVFLCEYEY | DVHWGSFKRV | AELADGDEDS | DQEWNGRKEE |
| 370 | 380 | 390 | 400 | 410 | 420 |
| EIDYSDEEIE | FDDEESVRGV | SKSKRGGANS | RKGRFFGLEK | VGMKRIPEHV | RCHKQSELEK |
| 430 | 440 | 450 | 460 | 470 | 480 |
| AKATLLLATR | PKSLPCRSKE | MEEITAFIKG | SISDDQCLGR | CMYIHGVPGT | GKTISVLSVM |
| 490 | 500 | 510 | 520 | 530 | 540 |
| KNLKAEVEAG | SVSPYCFVEI | NGLKLASPEN | IYSVIYEGLS | GHRVGWKKAL | QSLNERFAEG |
| 550 | 560 | 570 | 580 | 590 | 600 |
| KKIGKENEKP | CILLIDELDV | LVTRNQSVLY | NILDWPTKPN | SKLVVLGIAN | TMDLPEKLLP |
| 610 | 620 | 630 | 640 | 650 | 660 |
| RISSRMGIQR | LCFGPYNHRQ | LQEIISTRLE | GINAFEKTAI | EFASRKVAAI | SGDARRALEI |
| 670 | 680 | 690 | 700 | 710 | 720 |
| CRRAAEVADY | RLKKSNISAK | SQLVIMADVE | VAIQEMFQAP | HIQVMKSVSK | LSRIFLTAMV |
| 730 | 740 | 750 | 760 | 770 | 780 |
| HELYKTGMAE | TSFDRVATTV | SSICLTNGEA | FPGWDILLKI | GCDLGECRIV | LCEPGEKHRL |
| 790 | 800 | ||||
| QKLQLNFPSD | DVAFALKDNK | DLPWLANYL |