Q54SP2
Gene name |
forB |
Protein name |
Formin-B |
Names |
|
Species |
Dictyostelium discoideum (Slime mold) |
KEGG Pathway |
ddi:DDB_G0282297 |
EC number |
|
Protein Class |
|
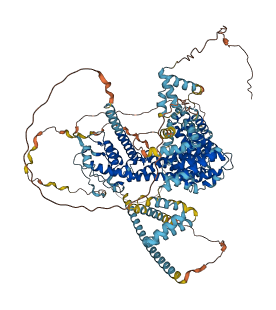
Descriptions
Autoinhibitory domains (AIDs)
Target domain |
612-1095 (FH2 domain) |
Relief mechanism |
Partner binding |
Assay |
|
Target domain |
612-1095 (FH2 domain) |
Relief mechanism |
Partner binding |
Assay |
|
Accessory elements
No accessory elements
Autoinhibited structure

Activated structure
1 structures for Q54SP2
| Entry ID | Method | Resolution | Chain | Position | Source |
|---|---|---|---|---|---|
| AF-Q54SP2-F1 | Predicted | AlphaFoldDB |
No variants for Q54SP2
| Variant ID(s) | Position | Change | Description | Diseaes Association | Provenance |
|---|---|---|---|---|---|
| No variants for Q54SP2 | |||||
No associated diseases with Q54SP2
1 GO annotations of cellular component
| Name | Definition |
|---|---|
| actin cytoskeleton | The part of the cytoskeleton (the internal framework of a cell) composed of actin and associated proteins. Includes actin cytoskeleton-associated complexes. |
3 GO annotations of molecular function
| Name | Definition |
|---|---|
| actin filament binding | Binding to an actin filament, also known as F-actin, a helical filamentous polymer of globular G-actin subunits. |
| profilin binding | Binding to profilin, an actin-binding protein that forms a complex with G-actin and prevents it from polymerizing to form F-actin. |
| small GTPase binding | Binding to a small monomeric GTPase. |
2 GO annotations of biological process
| Name | Definition |
|---|---|
| 'de novo' actin filament nucleation | The actin nucleation process in which actin monomers combine in the absence of any existing actin filaments; elongation of the actin oligomer formed by nucleation leads to the formation of an unbranched filament. |
| actin filament polymerization | Assembly of actin filaments by the addition of actin monomers to a filament. |
No homologous proteins in AiPD
| UniProt AC | Gene Name | Protein Name | Species | Evidence Code |
|---|---|---|---|---|
| No homologous proteins | ||||
| 10 | 20 | 30 | 40 | 50 | 60 |
| MFFKGKKKDK | EKEKSHGNIG | NVISVENKTG | SQSNLHVEQN | LSNEDLKIQF | SQLLYELGVP |
| 70 | 80 | 90 | 100 | 110 | 120 |
| EAKRVEMELW | SNDKKWMLLV | QNKDKIKENE | EKMKQKGSLY | ETPQFYLSLL | RENASIQKTI |
| 130 | 140 | 150 | 160 | 170 | 180 |
| SDLKVSLASN | KLSWIDSFIG | LSGFDEILKI | FQTFQLKPEK | NSIDFLILFD | CVNIIKSILN |
| 190 | 200 | 210 | 220 | 230 | 240 |
| SQSGVKSVMT | TSHTFKVLVL | CLDQSYPPEL | RNAVLQLTAA | LTLLPTVGHS | YVLEAIENFK |
| 250 | 260 | 270 | 280 | 290 | 300 |
| VSNREKVRFQ | TIIEGAKSVS | NTQLHYEYLT | SFMNLVNSIV | NSPADLQVRI | GLRSEFTALK |
| 310 | 320 | 330 | 340 | 350 | 360 |
| LIELISNSKG | VSEDLDTQIN | LFFECMEEDN | DEVGAHYKEV | NIRSPSEVST | KIDTLLQSHP |
| 370 | 380 | 390 | 400 | 410 | 420 |
| ALHHHFISII | KGLYTLASTQ | SDLGGSMWNI | LDESVGLILK | DPSKESQLEK | LQNENNNLKL |
| 430 | 440 | 450 | 460 | 470 | 480 |
| QLSEIKLNNS | NNNNNNNNSN | NNNNDSNVST | PNINTGSPLL | PPQQYQDLEQ | KLQLTQNEKN |
| 490 | 500 | 510 | 520 | 530 | 540 |
| ESQNKVKQLE | SEIKGLNSTL | TGLQLKVTKL | EADLLSVSVT | TPPSDTNGTT | SPPIEAPSSP |
| 550 | 560 | 570 | 580 | 590 | 600 |
| SLGAPPPPPP | PPPAPPVSGG | GPPPPPPPPP | PSSGGGPPPP | PPPPSSGGPP | PPPPPPGGMK |
| 610 | 620 | 630 | 640 | 650 | 660 |
| KPGAPAVPNL | PPKKSSVPSV | KMVGLQWKKV | NNNVIENSIW | MNVKDYNLND | QFKQLEELFQ |
| 670 | 680 | 690 | 700 | 710 | 720 |
| VKKPTATTPT | APVGGASNVA | VGGGSGSKSI | VSTPTISILD | PKRSQAIMIM | LSRFKISFPD |
| 730 | 740 | 750 | 760 | 770 | 780 |
| LSKAITNLDE | SKLNLEDAKS | LLKFVPSSEE | IELLKEEDPS | CFGKPEQFLW | ELSKINRISE |
| 790 | 800 | 810 | 820 | 830 | 840 |
| KLECFIFKQK | LSTQIEELTP | DINALLKGSM | ETKNNKSFHQ | ILEIVLSLGN | FINGGTPRGD |
| 850 | 860 | 870 | 880 | 890 | 900 |
| IYGFKLDSLS | GLLDCRSPSD | SKVTLMTWLI | QFLENKHPSL | LEFHQEFTAI | DEAKRVSIQN |
| 910 | 920 | 930 | 940 | 950 | 960 |
| LRSEVASLKK | GLTLLTNEVE | KSEGASKTIL | SGFVGKSTDA | VTLIEKQFNT | ALESFNSTVQ |
| 970 | 980 | 990 | 1000 | 1010 | 1020 |
| FYGEDVKTSS | PEEFFQHVSK | FKNEFKRTIE | SIQKERENVQ | KLAARKKAAA | SGPSVPSASG |
| 1030 | 1040 | 1050 | 1060 | 1070 | 1080 |
| SSINIAPKSG | VSPITPTSKS | SISISQKPPQ | STQPSISVQQ | QQQQHHGDDD | DDIPQNGTFM |
| 1090 | 1100 | 1110 | 1120 | ||
| DQLMSKMKGG | EAIRASRRAS | QYVFTQNGAG | GVGAIDALNA | ALKNKK |