P41162
Gene name |
ETV3 (METS, PE1) |
Protein name |
ETS translocation variant 3 |
Names |
ETS domain transcriptional repressor PE1, PE-1, Mitogenic Ets transcriptional suppressor |
Species |
Homo sapiens (Human) |
KEGG Pathway |
hsa:2117 |
EC number |
|
Protein Class |
|
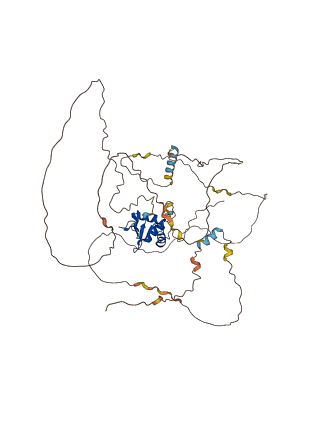
Descriptions
The autoinhibited protein was predicted that may have potential autoinhibitory elements via cis-regPred.
Autoinhibitory domains (AIDs)
Target domain |
|
Relief mechanism |
|
Assay |
cis-regPred |
Accessory elements
No accessory elements
Autoinhibited structure

Activated structure
1 structures for P41162
| Entry ID | Method | Resolution | Chain | Position | Source |
|---|---|---|---|---|---|
| AF-P41162-F1 | Predicted | AlphaFoldDB |
325 variants for P41162
| Variant ID(s) | Position | Change | Description | Diseaes Association | Provenance |
|---|---|---|---|---|---|
|
rs778557258 CA1173482 |
4 | G>S | No |
ClinGen ExAC gnomAD |
|
|
CA31133716 rs1018954526 |
5 | C>S | No |
ClinGen Ensembl |
|
|
CA342958651 rs1184509188 |
5 | C>Y | No |
ClinGen gnomAD |
|
|
CA342958638 rs1483419889 |
7 | I>V | No |
ClinGen gnomAD |
|
|
CA1173480 rs753632088 |
8 | V>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs757139556 CA1173481 |
8 | V>L | No |
ClinGen ExAC gnomAD |
|
|
rs757139556 CA342958632 |
8 | V>M | No |
ClinGen ExAC gnomAD |
|
| TCGA novel | 9 | E>K | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs1256324717 CA342958619 |
10 | K>E | No |
ClinGen TOPMed gnomAD |
|
|
rs752167309 CA1173477 |
14 | G>D | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs756064101 CA1173478 |
14 | G>S | No |
ClinGen ExAC gnomAD |
|
|
CA342958585 rs1191350515 |
15 | G>E | No |
ClinGen TOPMed gnomAD |
|
|
CA342958553 rs1571703021 |
18 | Q>R | No |
ClinGen Ensembl |
|
|
CA1173455 rs754584559 |
20 | P>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs889673367 CA31133245 |
21 | D>Y | No |
ClinGen TOPMed |
|
|
rs1369340775 CA342958514 |
23 | A>V | No |
ClinGen gnomAD |
|
|
CA342958509 rs1284178420 |
24 | Y>C | No |
ClinGen TOPMed gnomAD |
|
|
CA342958501 rs1442559657 |
25 | K>R | No |
ClinGen gnomAD |
|
|
rs1249614006 CA342958496 |
26 | T>A | No |
ClinGen gnomAD |
|
|
rs1188252135 CA342958487 |
27 | E>G | No |
ClinGen TOPMed |
|
|
rs201230416 CA1173452 |
28 | S>A | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA1173453 rs201230416 |
28 | S>T | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1211186991 CA342958474 |
29 | S>F | No |
ClinGen gnomAD |
|
|
rs1290594127 CA342958472 |
30 | P>A | No |
ClinGen TOPMed gnomAD |
|
| TCGA novel | 30 | P>L | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs1243255856 CA342958466 |
31 | G>R | No |
ClinGen TOPMed gnomAD |
|
|
CA1173449 rs762394656 |
32 | S>A | No |
ClinGen ExAC gnomAD |
|
|
rs1441447162 CA342958455 |
33 | R>Q | No |
ClinGen gnomAD |
|
|
rs1042519523 CA31133210 |
33 | R>W | No |
ClinGen TOPMed gnomAD |
|
|
CA342958438 rs1326421226 |
35 | I>M | No |
ClinGen gnomAD |
|
|
CA342958327 rs1163203810 |
51 | R>C | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen NCI-TCGA gnomAD |
|
CA1173445 rs775452231 |
51 | R>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA342958321 rs1289805610 |
52 | H>R | No |
ClinGen TOPMed |
|
|
rs374055229 CA1173442 |
55 | A>T | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA1173440 COSM1335049 COSM1335048 rs201844852 |
58 | Q>H | large_intestine [Cosmic] | No |
ClinGen cosmic curated 1000Genomes ExAC TOPMed gnomAD |
|
rs781118236 CA1173439 |
59 | G>* | No |
ClinGen ExAC gnomAD |
|
|
CA31133155 rs946758006 |
59 | G>E | No |
ClinGen Ensembl |
|
|
CA342958254 rs1176411953 |
62 | G>R | No |
ClinGen gnomAD |
|
|
rs1215597000 CA342958224 |
66 | I>F | No |
ClinGen gnomAD |
|
|
CA342958190 rs1571702774 |
70 | D>E | No |
ClinGen Ensembl |
|
|
CA342958186 rs1571702766 |
71 | E>G | No |
ClinGen Ensembl |
|
|
rs1571702763 CA342958174 |
73 | A>P | No |
ClinGen Ensembl |
|
|
rs751032829 CA1173437 |
74 | R>C | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA1173436 rs779743240 |
74 | R>H | No |
ClinGen ExAC |
|
|
CA1173435 rs758099773 |
78 | R>C | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs765692496 CA1173434 |
78 | R>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs765692496 CA1173433 |
78 | R>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
COSM1317651 COSM1317650 CA1173432 rs762200550 |
79 | R>K | haematopoietic_and_lymphoid_tissue [Cosmic] | No |
ClinGen cosmic curated ExAC gnomAD |
|
CA1173430 rs764608352 |
81 | C>R | No |
ClinGen ExAC gnomAD |
|
|
CA342958101 rs1171316915 |
84 | Q>R | No |
ClinGen gnomAD |
|
|
rs1174275110 CA342958042 |
92 | R>W | No |
ClinGen gnomAD |
|
|
rs775605192 CA1173428 |
93 | A>T | No |
ClinGen ExAC gnomAD |
|
|
CA342958029 rs1196732492 |
94 | L>P | No |
ClinGen gnomAD |
|
| TCGA novel | 96 | Y>* | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 96 | Y>C | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs749957817 CA1173417 |
96 | Y>H | No |
ClinGen ExAC gnomAD |
|
| TCGA novel | 102 | I>M | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs1553247183 CA342957952 |
103 | L>P | No |
ClinGen Ensembl |
|
|
rs756878385 CA1173415 |
106 | T>A | No |
ClinGen ExAC gnomAD |
|
|
CA1173414 rs754188589 |
106 | T>K | No |
ClinGen ExAC gnomAD |
|
|
rs1461992474 CA342957926 |
107 | K>T | No |
ClinGen gnomAD |
|
|
rs764404209 CA1173413 |
109 | K>N | No |
ClinGen ExAC gnomAD |
|
| TCGA novel | 113 | Y>H | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA342957848 COSM175953 rs1571701674 COSM175952 TCGA novel |
117 | F>L | Variant assessed as Somatic; impact. large_intestine [NCI-TCGA, Cosmic] | No |
NCI-TCGA ClinGen cosmic curated Ensembl |
|
rs377498585 CA1173411 |
118 | N>S | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA1173412 rs761226318 |
118 | N>Y | No |
ClinGen ExAC TOPMed |
|
|
rs759549727 CA1173409 |
119 | K>N | No |
ClinGen ExAC gnomAD |
|
|
rs201364337 CA1173408 |
121 | V>G | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA342957823 rs1393323315 |
122 | M>L | No |
ClinGen TOPMed |
|
|
CA342957806 rs980425502 |
124 | N>S | No |
ClinGen TOPMed gnomAD |
|
|
CA31131670 rs980425502 |
124 | N>T | No |
ClinGen TOPMed gnomAD |
|
|
rs766539831 CA1173407 |
128 | I>V | No |
ClinGen ExAC gnomAD |
|
|
rs1320412469 CA342957770 |
129 | N>S | No |
ClinGen TOPMed |
|
|
rs35010936 CA1173406 |
130 | I>V | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
rs768391921 CA1173404 |
131 | R>Q | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs142863577 CA1173405 |
131 | R>W | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA342957750 rs1242871898 |
133 | S>G | No |
ClinGen TOPMed |
|
|
CA342956917 rs1223278264 |
138 | Q>H | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen NCI-TCGA gnomAD |
|
CA342956896 rs1289848509 |
142 | P>S | No |
ClinGen TOPMed gnomAD |
|
|
rs74407035 CA1173386 |
145 | T>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs74407035 CA31125287 |
145 | T>P | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1294797756 CA342956872 |
146 | A>S | No |
ClinGen gnomAD |
|
|
CA1173385 rs373438614 |
146 | A>V | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1424147555 CA342956868 |
147 | S>T | No |
ClinGen TOPMed |
|
|
CA1173384 rs760328254 |
149 | R>Q | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1343103303 CA342956856 COSM3802291 |
149 | R>W | Variant assessed as Somatic; impact. breast [NCI-TCGA, Cosmic] | No |
ClinGen cosmic curated NCI-TCGA TOPMed gnomAD |
|
CA342956843 rs1303280543 |
151 | H>Y | No |
ClinGen TOPMed gnomAD |
|
|
rs1403780047 CA342956830 |
152 | F>L | No |
ClinGen gnomAD |
|
|
rs775444448 CA1173383 |
153 | P>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA342956795 rs1419790284 |
158 | H>R | No |
ClinGen TOPMed gnomAD |
|
|
rs1463868333 CA342956784 |
160 | P>A | No |
ClinGen gnomAD |
|
|
rs887512064 CA31125267 |
162 | N>S | No |
ClinGen TOPMed gnomAD |
|
|
CA1173381 rs745838244 |
163 | D>E | No |
ClinGen ExAC gnomAD |
|
|
rs1427305629 CA342956759 |
164 | V>L | No |
ClinGen gnomAD |
|
|
CA1173380 rs555388242 |
165 | Q>H | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
COSM897514 CA31125188 rs1041008780 |
166 | P>L | endometrium [Cosmic] | No |
ClinGen cosmic curated TOPMed gnomAD |
|
rs148187329 CA31125235 |
166 | P>S | No |
ClinGen 1000Genomes TOPMed gnomAD |
|
|
CA1173379 rs770409062 |
168 | R>Q | No |
ClinGen ExAC gnomAD |
|
|
CA31125183 rs776355540 |
168 | R>W | No |
ClinGen gnomAD |
|
|
CA342956724 rs1313935965 |
170 | S>P | No |
ClinGen gnomAD |
|
|
CA342956709 rs1342004552 |
172 | S>T | No |
ClinGen TOPMed |
|
|
CA31125156 rs1008051818 |
174 | L>P | No |
ClinGen TOPMed gnomAD |
|
|
rs886974256 CA31125148 |
176 | A>V | No |
ClinGen gnomAD |
|
|
rs1298014165 CA342956658 |
180 | E>D | No |
ClinGen gnomAD |
|
|
CA342956663 rs1485076907 |
180 | E>Q | No |
ClinGen gnomAD |
|
|
CA342956642 rs1460776055 |
183 | N>D | No |
ClinGen TOPMed gnomAD |
|
|
CA342956638 rs1571696111 |
183 | N>S | No |
ClinGen Ensembl |
|
|
CA342956631 rs1260371700 |
184 | G>D | No |
ClinGen gnomAD |
|
|
CA342956617 rs1480162572 |
186 | D>G | No |
ClinGen gnomAD |
|
|
rs1177702327 CA342956622 |
186 | D>N | No |
ClinGen gnomAD |
|
|
CA342956619 rs1480162572 |
186 | D>V | No |
ClinGen gnomAD |
|
|
CA342956609 rs1356022713 |
187 | R>S | No |
ClinGen gnomAD |
|
|
rs1184041428 CA342956602 |
188 | K>N | No |
ClinGen gnomAD |
|
|
CA1173377 rs557928052 |
188 | K>R | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
| TCGA novel | 188 | K>T | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs1253551181 CA342956590 |
190 | E>G | No |
ClinGen TOPMed |
|
|
rs1558029321 CA342956584 |
191 | L>F | No |
ClinGen Ensembl |
|
|
rs1571696076 CA342956568 |
193 | E>D | No |
ClinGen Ensembl |
|
|
CA31125112 rs200806018 |
195 | E>K | No |
ClinGen Ensembl |
|
|
rs770499225 CA31125097 |
197 | G>C | No |
ClinGen gnomAD |
|
|
rs1558029311 CA342956544 |
197 | G>D | No |
ClinGen Ensembl |
|
|
CA342956536 rs1166194726 |
198 | S>L | Variant assessed as Somatic; impact. [NCI-TCGA] | No |
ClinGen NCI-TCGA TOPMed |
|
CA342956534 rs1421081835 |
199 | A>P | No |
ClinGen TOPMed |
|
|
rs761046793 CA31125087 |
200 | A>T | No |
ClinGen Ensembl |
|
|
rs748464669 CA1173375 |
203 | R>C | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA1173374 rs377466641 |
203 | R>H | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen ESP ExAC NCI-TCGA TOPMed gnomAD |
|
CA31125074 rs773478194 |
204 | R>Q | No |
ClinGen TOPMed gnomAD |
|
|
rs937563864 CA31125076 |
204 | R>W | No |
ClinGen gnomAD |
|
|
CA31125059 rs935424865 |
205 | G>S | No |
ClinGen TOPMed |
|
|
rs925376464 CA31125057 |
207 | D>H | No |
ClinGen TOPMed gnomAD |
|
|
CA31125045 rs879935210 |
209 | V>G | No |
ClinGen Ensembl |
|
|
COSM1205748 CA31125056 rs776514941 |
209 | V>M | large_intestine [Cosmic] | No |
ClinGen cosmic curated TOPMed gnomAD |
|
CA342956466 rs1571696016 |
211 | S>T | No |
ClinGen Ensembl |
|
| TCGA novel | 212 | R>S | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA342956445 rs1400222684 |
214 | A>T | No |
ClinGen gnomAD |
|
|
rs1385367320 CA342956434 |
215 | I>T | No |
ClinGen gnomAD |
|
|
CA342956423 rs1469774562 |
217 | G>E | No |
ClinGen gnomAD |
|
|
CA342956426 rs1337993568 |
217 | G>R | No |
ClinGen gnomAD |
|
|
CA1173372 rs752110496 |
219 | G>R | No |
ClinGen ExAC gnomAD |
|
|
CA1173371 rs539187606 |
220 | I>T | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA342956393 rs1454367145 |
222 | H>R | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen NCI-TCGA gnomAD |
|
CA31124982 rs969206384 |
225 | R>C | No |
ClinGen TOPMed |
|
|
CA1173370 rs772524539 |
225 | R>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA342956181 CA342956180 rs2231856 |
234 | F>L | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA1173368 rs553405510 |
235 | A>T | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs1186634227 CA342956156 |
236 | R>K | No |
ClinGen TOPMed |
|
|
CA31124903 CA1173367 rs2231857 |
239 | M>I | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA31124953 rs1015024707 |
239 | M>R | No |
ClinGen TOPMed gnomAD |
|
|
rs1571695957 CA342956077 |
240 | Y>S | No |
ClinGen Ensembl |
|
| TCGA novel | 241 | P>S | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA342956038 rs1571695945 |
242 | D>A | No |
ClinGen Ensembl |
|
|
CA31124892 rs887552154 |
243 | P>R | No |
ClinGen TOPMed |
|
|
CA31124871 rs1019535310 |
244 | H>Q | No |
ClinGen TOPMed gnomAD |
|
|
rs752505369 CA1173366 |
244 | H>Y | No |
ClinGen ExAC gnomAD |
|
|
CA342955982 rs1388430008 |
245 | S>G | No |
ClinGen TOPMed |
|
|
rs535102929 CA342955941 |
247 | F>L | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs568015565 CA1173364 |
248 | A>T | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs900017948 CA31124839 |
249 | V>I | No |
ClinGen TOPMed |
|
|
rs886900522 CA31124821 |
252 | I>F | No |
ClinGen TOPMed gnomAD |
|
|
rs886900522 CA31124837 |
252 | I>V | No |
ClinGen TOPMed gnomAD |
|
|
CA342955819 rs1382857377 |
255 | R>C | No |
ClinGen TOPMed gnomAD |
|
|
rs770908483 CA1173362 COSM1600997 |
255 | R>H | liver [Cosmic] | No |
ClinGen cosmic curated ExAC TOPMed gnomAD |
|
rs183796584 CA1173360 |
256 | G>R | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen 1000Genomes ESP ExAC NCI-TCGA TOPMed gnomAD |
|
CA31124778 rs891347836 |
261 | V>I | No |
ClinGen TOPMed gnomAD |
|
|
rs756568722 CA31124747 |
262 | P>A | No |
ClinGen gnomAD |
|
|
CA342955700 rs1259102986 |
262 | P>R | No |
ClinGen gnomAD |
|
|
rs937344046 CA31124738 |
263 | I>V | No |
ClinGen TOPMed |
|
|
CA342955611 rs1290573409 |
271 | P>R | No |
ClinGen gnomAD |
|
|
rs935325741 CA31124730 |
272 | T>I | No |
ClinGen TOPMed |
|
|
rs769073682 CA1173356 |
273 | I>V | No |
ClinGen ExAC gnomAD |
|
|
CA31124728 rs552811475 |
276 | Y>C | No |
ClinGen 1000Genomes TOPMed |
|
|
rs1357060130 CA342955541 |
278 | P>L | No |
ClinGen TOPMed gnomAD |
|
|
CA342955544 rs1272449617 |
278 | P>S | No |
ClinGen gnomAD |
|
|
rs1228740609 CA342955535 |
279 | S>L | No |
ClinGen gnomAD |
|
|
rs1326329139 CA342955534 |
280 | P>S | No |
ClinGen gnomAD |
|
|
rs1558029136 CA342955518 |
282 | L>R | No |
ClinGen Ensembl |
|
|
CA342955513 rs1188266667 |
283 | S>T | No |
ClinGen TOPMed |
|
|
rs747376820 CA1173355 |
284 | P>A | No |
ClinGen ExAC gnomAD |
|
|
rs560588208 CA1173353 |
287 | S>N | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs1302711208 CA342955468 |
289 | S>R | No |
ClinGen gnomAD |
|
|
CA342955433 rs1421326586 |
294 | N>S | No |
ClinGen gnomAD |
|
|
CA342955425 rs1558029109 |
295 | P>L | No |
ClinGen Ensembl |
|
| TCGA novel | 296 | E>K | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs1168249454 CA342955326 |
304 | S>A | No |
ClinGen TOPMed gnomAD |
|
|
rs530073499 CA31124667 |
304 | S>F | No |
ClinGen 1000Genomes |
|
|
rs1246877853 CA342955293 |
307 | C>F | No |
ClinGen gnomAD |
|
|
rs1332743821 CA342955251 |
311 | N>S | No |
ClinGen TOPMed |
|
|
CA342955223 rs1371252211 |
313 | H>R | No |
ClinGen gnomAD |
|
|
rs1267744528 CA342955176 |
317 | R>Q | No |
ClinGen gnomAD |
|
|
rs371717247 CA31124658 |
319 | F>L | No |
ClinGen ESP TOPMed gnomAD |
|
|
CA1173351 rs779086898 |
321 | R>C | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs757527481 CA1173350 |
321 | R>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs757527481 CA342955133 |
321 | R>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA342955130 rs1196726483 |
322 | Y>H | No |
ClinGen gnomAD |
|
|
CA342955106 rs1339377963 |
323 | P>L | No |
ClinGen gnomAD |
|
|
CA1173348 rs767419115 |
324 | G>E | No |
ClinGen ExAC gnomAD |
|
|
CA342955071 rs983547959 |
326 | M>L | No |
ClinGen TOPMed gnomAD |
|
|
rs1282909593 CA342955063 |
326 | M>R | No |
ClinGen gnomAD |
|
|
CA31124640 rs983547959 |
326 | M>V | No |
ClinGen TOPMed gnomAD |
|
|
rs759341794 CA1173347 |
327 | V>F | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs759341794 CA342955055 |
327 | V>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1027698872 CA31124639 |
330 | L>V | No |
ClinGen TOPMed |
|
|
rs1329359246 CA342955000 |
331 | Q>H | No |
ClinGen gnomAD |
|
|
CA342954969 rs1398026725 |
334 | M>V | No |
ClinGen gnomAD |
|
|
CA342954955 rs1178429505 |
335 | H>N | No |
ClinGen gnomAD |
|
|
rs1342010336 CA342954896 |
339 | S>A | No |
ClinGen gnomAD |
|
|
rs1196607807 CA342954885 |
340 | T>A | No |
ClinGen gnomAD |
|
|
rs1196607807 CA342954887 |
340 | T>P | No |
ClinGen gnomAD |
|
|
CA342954869 rs1300853688 |
341 | Q>P | No |
ClinGen gnomAD |
|
|
rs1558029036 CA342954839 |
343 | S>P | No |
ClinGen Ensembl |
|
|
CA342954821 rs1233086853 |
344 | I>M | No |
ClinGen gnomAD |
|
|
CA342954816 rs1205746558 |
345 | K>R | No |
ClinGen gnomAD |
|
|
rs1256737023 CA342954812 |
346 | L>M | No |
ClinGen gnomAD |
|
|
rs1206073706 CA342954799 |
348 | P>S | No |
ClinGen gnomAD |
|
|
CA342954781 rs1571695617 |
351 | V>I | No |
ClinGen Ensembl |
|
|
rs1262640117 CA342954761 |
354 | K>R | No |
ClinGen gnomAD |
|
|
CA31124634 rs995884247 |
356 | R>Q | No |
ClinGen TOPMed gnomAD |
|
|
CA342954729 rs1280287731 |
359 | V>L | No |
ClinGen gnomAD |
|
|
rs766182214 CA1173345 |
360 | E>D | No |
ClinGen ExAC gnomAD |
|
|
rs751387992 CA1173346 |
360 | E>V | No |
ClinGen ExAC gnomAD |
|
|
CA342954700 rs1470284451 |
363 | E>K | No |
ClinGen gnomAD |
|
|
CA31124617 rs964406104 |
364 | E>D | No |
ClinGen TOPMed |
|
|
CA1173344 rs762980071 |
365 | S>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA1173343 rs377154346 |
367 | P>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA342954674 rs377154346 |
367 | P>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs377154346 CA342954675 |
367 | P>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1236691440 COSM1194866 CA342954653 |
370 | T>M | lung [Cosmic] | No |
ClinGen cosmic curated TOPMed gnomAD |
|
CA31124559 rs746780106 |
371 | P>H | No |
ClinGen Ensembl |
|
|
rs1234423682 CA342954643 |
372 | T>N | No |
ClinGen TOPMed |
|
|
CA1173342 rs562878710 |
373 | M>V | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs1243063621 CA342954633 |
374 | A>T | No |
ClinGen TOPMed gnomAD |
|
|
rs779195722 CA31124529 |
376 | I>F | No |
ClinGen gnomAD |
|
|
rs776198124 CA1173340 |
380 | I>N | No |
ClinGen ExAC gnomAD |
|
|
CA342954590 rs1171807681 |
381 | K>E | No |
ClinGen gnomAD |
|
|
rs1197134429 CA342954579 |
382 | V>A | No |
ClinGen TOPMed |
|
|
rs1197134429 CA342954580 |
382 | V>G | No |
ClinGen TOPMed |
|
|
rs576275620 CA1173339 |
382 | V>L | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
rs780498765 CA1173337 |
383 | E>D | No |
ClinGen ExAC gnomAD |
|
|
rs1255452349 CA342954568 |
384 | P>S | No |
ClinGen TOPMed |
|
|
rs557591754 CA31124394 |
385 | A>T | No |
ClinGen 1000Genomes |
|
|
CA31124388 rs372706068 |
390 | P>L | No |
ClinGen gnomAD |
|
|
CA342954529 rs1432305060 |
390 | P>S | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen NCI-TCGA gnomAD |
|
CA342954515 rs1455056185 |
392 | S>G | No |
ClinGen TOPMed |
|
|
rs545598508 CA1173336 |
393 | L>F | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen 1000Genomes ExAC NCI-TCGA TOPMed gnomAD |
|
CA31124386 rs898349818 |
393 | L>P | No |
ClinGen TOPMed gnomAD |
|
|
rs1165934044 CA342954484 |
396 | S>L | No |
ClinGen TOPMed gnomAD |
|
|
CA342954485 rs1165934044 |
396 | S>W | No |
ClinGen TOPMed gnomAD |
|
|
CA31124371 rs1034429249 |
398 | R>Q | No |
ClinGen TOPMed |
|
|
rs1256081723 CA342954463 |
400 | K>E | No |
ClinGen gnomAD |
|
|
rs1373124688 CA342954457 |
401 | E>K | No |
ClinGen TOPMed |
|
|
CA342954438 rs1180571620 |
403 | H>P | No |
ClinGen gnomAD |
|
|
rs1441609020 CA342954439 |
403 | H>Y | No |
ClinGen TOPMed |
|
|
rs778841429 CA1173334 |
404 | T>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs778841429 CA31124347 |
404 | T>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA31124340 rs903862826 |
407 | E>A | No |
ClinGen TOPMed |
|
|
rs1228952117 CA342954359 |
408 | G>V | No |
ClinGen TOPMed |
|
|
CA342954352 rs1251540178 |
409 | T>A | No |
ClinGen TOPMed |
|
|
CA1173333 rs757475929 |
411 | P>L | No |
ClinGen ExAC gnomAD |
|
|
CA342954321 rs757475929 |
411 | P>R | No |
ClinGen ExAC gnomAD |
|
|
CA342954293 rs1246445102 |
413 | R>K | No |
ClinGen gnomAD |
|
|
CA1173331 rs778086102 |
414 | T>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA342954261 rs1188532641 |
415 | I>T | No |
ClinGen TOPMed |
|
|
rs1430436652 CA342954163 |
420 | G>D | No |
ClinGen TOPMed |
|
|
CA342954142 rs1368145854 |
422 | I>V | No |
ClinGen TOPMed |
|
|
CA342954093 rs1362538830 |
425 | R>C | No |
ClinGen TOPMed gnomAD |
|
|
rs540027756 CA31124294 |
425 | R>H | No |
ClinGen TOPMed gnomAD |
|
|
rs540027756 CA342954086 |
425 | R>L | No |
ClinGen TOPMed gnomAD |
|
|
CA342954033 rs1319869480 |
429 | P>S | No |
ClinGen TOPMed |
|
|
CA342954022 rs1367053054 |
430 | P>A | No |
ClinGen gnomAD |
|
|
CA342954008 rs1303316150 |
431 | I>V | No |
ClinGen gnomAD |
|
|
CA1173329 rs751272378 |
435 | V>G | No |
ClinGen ExAC |
|
|
CA31124284 rs939180582 |
435 | V>L | No |
ClinGen TOPMed |
|
|
CA342953935 rs939180582 |
435 | V>M | No |
ClinGen TOPMed |
|
|
rs1295632114 CA342953871 |
438 | S>G | No |
ClinGen TOPMed |
|
|
rs983381126 CA31124235 |
444 | P>L | No |
ClinGen TOPMed |
|
|
rs1425707725 CA342953796 |
446 | E>K | No |
ClinGen TOPMed gnomAD |
|
|
rs1368216240 CA342953786 |
446 | E>V | No |
ClinGen gnomAD |
|
| TCGA novel | 447 | V>M | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA1173328 rs766238220 |
448 | T>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs371357999 CA31124233 |
450 | D>Y | No |
ClinGen 1000Genomes ESP TOPMed gnomAD |
|
|
CA31124230 rs892030089 |
452 | E>K | No |
ClinGen TOPMed gnomAD |
|
|
CA342953668 rs1259500990 |
453 | D>E | No |
ClinGen TOPMed |
|
|
CA342953671 rs1193127184 |
453 | D>G | No |
ClinGen gnomAD |
|
|
CA31124224 rs1055144689 |
454 | R>K | No |
ClinGen Ensembl |
|
|
rs1476844805 CA342953646 |
455 | P>L | No |
ClinGen gnomAD |
|
|
CA342953639 rs1271339368 |
456 | G>S | No |
ClinGen gnomAD |
|
|
rs200902536 CA1173327 |
457 | K>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs750434785 CA1173326 |
458 | E>D | No |
ClinGen ExAC gnomAD |
|
|
rs1205813426 CA342953422 |
467 | D>V | No |
ClinGen TOPMed |
|
|
rs1216265230 CA342953329 |
471 | P>H | No |
ClinGen gnomAD |
|
|
rs1474248851 CA342953302 |
473 | K>E | No |
ClinGen TOPMed |
|
| rs1346789939 | 473 | K>S | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
COSM160844 rs1558028778 CA342953244 |
476 | L>F | NS [Cosmic] | No |
ClinGen cosmic curated Ensembl |
|
CA342953235 rs1475419339 |
477 | K>R | No |
ClinGen TOPMed |
|
|
CA342953226 rs1463850997 |
478 | R>Q | No |
ClinGen gnomAD |
|
|
rs758268600 CA31124190 |
478 | R>W | No |
ClinGen gnomAD |
|
|
CA1173322 rs763695411 |
479 | R>C | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1170521391 CA342953193 |
480 | W>L | No |
ClinGen TOPMed gnomAD |
|
|
CA31124187 rs796138900 |
480 | W>R | No |
ClinGen Ensembl |
|
|
rs1400244304 CA342953146 |
482 | D>E | No |
ClinGen gnomAD |
|
|
rs1476895493 CA342953120 |
483 | D>E | No |
ClinGen gnomAD |
|
|
rs1455241197 CA342953107 |
484 | P>S | No |
ClinGen TOPMed |
|
|
rs1467522416 CA342953072 |
486 | A>T | No |
ClinGen TOPMed gnomAD |
|
|
CA342953055 rs1200199992 |
487 | R>* | No |
ClinGen TOPMed gnomAD |
|
|
CA342953056 rs1200199992 |
487 | R>G | No |
ClinGen TOPMed gnomAD |
|
|
rs775691553 CA1173320 |
487 | R>Q | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA342953022 rs1355635834 |
489 | L>Q | No |
ClinGen TOPMed |
|
| TCGA novel | 490 | S>R | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs772542929 CA1173319 |
492 | S>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs868783613 CA31124146 |
494 | K>R | No |
ClinGen gnomAD |
|
|
CA342952906 rs1257367958 |
495 | F>L | No |
ClinGen gnomAD |
|
|
CA342952864 rs1379493096 |
496 | L>P | No |
ClinGen TOPMed gnomAD |
|
|
rs746353974 CA1173318 |
497 | W>* | No |
ClinGen ExAC gnomAD |
|
|
CA342952785 rs1383991341 |
499 | G>E | No |
ClinGen Ensembl |
|
|
CA342952790 rs1319081189 |
499 | G>R | No |
ClinGen TOPMed |
|
|
CA342952692 rs1237495289 |
503 | Q>R | No |
ClinGen TOPMed gnomAD |
|
| TCGA novel | 503 | Q>R | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA342952682 rs1222358633 |
504 | G>S | No |
ClinGen gnomAD |
|
|
CA31124083 rs999786539 |
505 | L>S | No |
ClinGen TOPMed gnomAD |
|
|
rs1329061133 CA342952639 |
507 | T>A | No |
ClinGen TOPMed gnomAD |
|
|
rs904081440 CA31124075 |
507 | T>I | No |
ClinGen TOPMed |
|
|
rs1329061133 CA342952637 |
507 | T>S | No |
ClinGen TOPMed gnomAD |
|
|
CA342952618 rs1308614818 |
508 | A>V | No |
ClinGen gnomAD |
|
|
CA342952597 rs1374449343 |
512 | A>T | No |
ClinGen gnomAD |
|
| TCGA novel | 512 | A>V | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
No associated diseases with P41162
1 regional properties for P41162
| Type | Name | Position | InterPro Accession |
|---|---|---|---|
| domain | Ets domain | 34 - 120 | IPR000418 |
5 GO annotations of cellular component
| Name | Definition |
|---|---|
| chromatin | The ordered and organized complex of DNA, protein, and sometimes RNA, that forms the chromosome. |
| intracellular membrane-bounded organelle | Organized structure of distinctive morphology and function, bounded by a single or double lipid bilayer membrane and occurring within the cell. Includes the nucleus, mitochondria, plastids, vacuoles, and vesicles. Excludes the plasma membrane. |
| nucleoplasm | That part of the nuclear content other than the chromosomes or the nucleolus. |
| nucleus | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| RNA polymerase II transcription repressor complex | A protein complex, located in the nucleus, that possesses activity that prevents or downregulates transcription from a RNA polymerase II promoter. |
5 GO annotations of molecular function
| Name | Definition |
|---|---|
| DEAD/H-box RNA helicase binding | Binding to a DEAD/H-box RNA helicase. |
| DNA-binding transcription factor activity, RNA polymerase II-specific | A DNA-binding transcription factor activity that modulates the transcription of specific gene sets transcribed by RNA polymerase II. |
| DNA-binding transcription repressor activity, RNA polymerase II-specific | A DNA-binding transcription factor activity that represses or decreases the transcription of specific gene sets transcribed by RNA polymerase II. |
| RNA polymerase II transcription regulatory region sequence-specific DNA binding | Binding to a specific sequence of DNA that is part of a regulatory region that controls the transcription of a gene or cistron by RNA polymerase II. |
| sequence-specific double-stranded DNA binding | Binding to double-stranded DNA of a specific nucleotide composition, e.g. GC-rich DNA binding, or with a specific sequence motif or type of DNA, e.g. promotor binding or rDNA binding. |
4 GO annotations of biological process
| Name | Definition |
|---|---|
| cell differentiation | The process in which relatively unspecialized cells, e.g. embryonic or regenerative cells, acquire specialized structural and/or functional features that characterize the cells, tissues, or organs of the mature organism or some other relatively stable phase of the organism's life history. Differentiation includes the processes involved in commitment of a cell to a specific fate and its subsequent development to the mature state. |
| cellular response to granulocyte macrophage colony-stimulating factor stimulus | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a granulocyte macrophage colony-stimulating factor stimulus. |
| negative regulation of cell population proliferation | Any process that stops, prevents or reduces the rate or extent of cell proliferation. |
| regulation of transcription by RNA polymerase II | Any process that modulates the frequency, rate or extent of transcription mediated by RNA polymerase II. |
40 homologous proteins in AiPD
| UniProt AC | Gene Name | Protein Name | Species | Evidence Code |
|---|---|---|---|---|
| A1A4L6 | ETS2 | Protein C-ets-2 | Bos taurus (Bovine) | SS |
| Q2KIC2 | ETV1 | ETS translocation variant 1 | Bos taurus (Bovine) | SS |
| P15062 | ETS1 | Transforming protein p68/c-ets-1 | Gallus gallus (Chicken) | SS |
| P10157 | ETS2 | Protein C-ets-2 | Gallus gallus (Chicken) | SS |
| Q90837 | ERG | Transcriptional regulator Erg | Gallus gallus (Chicken) | SS |
| A2T762 | ETV3 | ETS translocation variant 3 | Pan troglodytes (Chimpanzee) | PR |
| Q04688 | Ets97D | DNA-binding protein Ets97D | Drosophila melanogaster (Fruit fly) | PR |
| Q9Y603 | ETV7 | Transcription factor ETV7 | Homo sapiens (Human) | SS |
| P41212 | ETV6 | Transcription factor ETV6 | Homo sapiens (Human) | SS |
| P78545 | ELF3 | ETS-related transcription factor Elf-3 | Homo sapiens (Human) | SS |
| Q9UKW6 | ELF5 | ETS-related transcription factor Elf-5 | Homo sapiens (Human) | EV |
| P32519 | ELF1 | ETS-related transcription factor Elf-1 | Homo sapiens (Human) | PR |
| Q99607 | ELF4 | ETS-related transcription factor Elf-4 | Homo sapiens (Human) | PR |
| Q06546 | GABPA | GA-binding protein alpha chain | Homo sapiens (Human) | SS |
| O95238 | SPDEF | SAM pointed domain-containing Ets transcription factor | Homo sapiens (Human) | PR |
| P50548 | ERF | ETS domain-containing transcription factor ERF | Homo sapiens (Human) | PR |
| P11308 | ERG | Transcriptional regulator ERG | Homo sapiens (Human) | EV |
| P43268 | ETV4 | ETS translocation variant 4 | Homo sapiens (Human) | EV |
| P41161 | ETV5 | ETS translocation variant 5 | Homo sapiens (Human) | SS |
| P50549 | ETV1 | ETS translocation variant 1 | Homo sapiens (Human) | EV |
| P41970 | ELK3 | ETS domain-containing protein Elk-3 | Homo sapiens (Human) | SS |
| P28324 | ELK4 | ETS domain-containing protein Elk-4 | Homo sapiens (Human) | EV |
| P19419 | ELK1 | ETS domain-containing protein Elk-1 | Homo sapiens (Human) | EV |
| P15036 | ETS2 | Protein C-ets-2 | Homo sapiens (Human) | EV |
| P14921 | ETS1 | Protein C-ets-1 | Homo sapiens (Human) | EV |
| P41971 | Elk3 | ETS domain-containing protein Elk-3 | Mus musculus (Mouse) | EV |
| Q00422 | Gabpa | GA-binding protein alpha chain | Mus musculus (Mouse) | EV |
| P41969 | Elk1 | ETS domain-containing protein Elk-1 | Mus musculus (Mouse) | PR |
| P28322 | Etv4 | ETS translocation variant 4 | Mus musculus (Mouse) | SS |
| P15037 | Ets2 | Protein C-ets-2 | Mus musculus (Mouse) | SS |
| P27577 | Ets1 | Protein C-ets-1 | Mus musculus (Mouse) | EV |
| P70459 | Erf | ETS domain-containing transcription factor ERF | Mus musculus (Mouse) | PR |
| Q9CXC9 | Etv5 | ETS translocation variant 5 | Mus musculus (Mouse) | SS |
| P41158 | Elk4 | ETS domain-containing protein Elk-4 | Mus musculus (Mouse) | PR |
| P41164 | Etv1 | ETS translocation variant 1 | Mus musculus (Mouse) | SS |
| P81270 | Erg | Transcriptional regulator ERG | Mus musculus (Mouse) | SS |
| P41156 | Ets1 | Protein C-ets-1 | Rattus norvegicus (Rat) | SS |
| A4GTP4 | Elk1 | ETS domain-containing protein Elk-1 | Rattus norvegicus (Rat) | PR |
| Q9PUQ1 | etv4 | ETS translocation variant 4 | Danio rerio (Zebrafish) (Brachydanio rerio) | SS |
| A3FEM2 | fev | Protein FEV | Danio rerio (Zebrafish) (Brachydanio rerio) | PR |
| 10 | 20 | 30 | 40 | 50 | 60 |
| MKAGCSIVEK | PEGGGGYQFP | DWAYKTESSP | GSRQIQLWHF | ILELLQKEEF | RHVIAWQQGE |
| 70 | 80 | 90 | 100 | 110 | 120 |
| YGEFVIKDPD | EVARLWGRRK | CKPQMNYDKL | SRALRYYYNK | RILHKTKGKR | FTYKFNFNKL |
| 130 | 140 | 150 | 160 | 170 | 180 |
| VMPNYPFINI | RSSGVVPQSA | PPVPTASSRF | HFPPLDTHSP | TNDVQPGRFS | ASSLTASGQE |
| 190 | 200 | 210 | 220 | 230 | 240 |
| SSNGTDRKTE | LSELEDGSAA | DWRRGVDPVS | SRNAIGGGGI | GHQKRKPDIM | LPLFARPGMY |
| 250 | 260 | 270 | 280 | 290 | 300 |
| PDPHSPFAVS | PIPGRGGVLN | VPISPALSLT | PTIFSYSPSP | GLSPFTSSSC | FSFNPEEMKH |
| 310 | 320 | 330 | 340 | 350 | 360 |
| YLHSQACSVF | NYHLSPRTFP | RYPGLMVPPL | QCQMHPEEST | QFSIKLQPPP | VGRKNRERVE |
| 370 | 380 | 390 | 400 | 410 | 420 |
| SSEESAPVTT | PTMASIPPRI | KVEPASEKDP | ESLRQSAREK | EEHTQEEGTV | PSRTIEEEKG |
| 430 | 440 | 450 | 460 | 470 | 480 |
| TIFARPAAPP | IWPSVPISTP | SGEPLEVTED | SEDRPGKEPS | APEKKEDALM | PPKLRLKRRW |
| 490 | 500 | 510 | |||
| NDDPEARELS | KSGKFLWNGS | GPQGLATAAA | DA |