P17252
Gene name |
PRKCA (PKCA, PRKACA) |
Protein name |
Protein kinase C alpha type |
Names |
PKC-A, PKC-alpha |
Species |
Homo sapiens (Human) |
KEGG Pathway |
hsa:5578 |
EC number |
2.7.11.13: Protein-serine/threonine kinases |
Protein Class |
SERINE/THREONINE-PROTEIN KINASE (PTHR24356) |
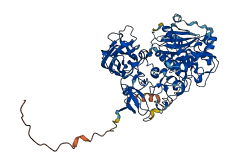
Descriptions
PRKCA encodes for Protein kinase C (PKC) alpha type belonging to the PCKs family and is involved in various cellular processes, including cell growth, immune response, muscle contraction, and synaptic plasticity. A well-known autoinhibitory region of the PKC family is a pseudosubstrate sequence at residues 1-30 that directly interacts with and blocks the catalytic activity of the kinase domain. Subsequences of the pseudosubstrate region are the C1 domains (C1A and C1B that bind diacylglycerol (DAG)), and the C2 domain (which binds to anionic phospholipids in a Ca2+-dependent manner). The C1A (residues 31-100) domain coordinates a network of domain-domain intramolecular interactions, including direct C1A-C2 contacts. The pseudosubstrate and C1A domains function as a single functional unit and are required to maintain autoinhibition. Additionally, the absence of the C1A domain significantly increases basal activity.
Autoinhibitory domains (AIDs)
Target domain |
328-668 (Catalytic domain of the Serine/Threonine Kinase, Classical Protein Kinase C alpha) |
Relief mechanism |
Ligand binding |
Assay |
Mutagenesis experiment, Deletion assay, Structural analysis |
Target domain |
328-668 (Catalytic domain of the Serine/Threonine Kinase, Classical Protein Kinase C alpha) |
Relief mechanism |
Ligand binding |
Assay |
Mutagenesis experiment, Deletion assay |
Accessory elements
480-503 (Activation loop from InterPro)
Target domain |
328-668 (Catalytic domain of the Serine/Threonine Kinase, Classical Protein Kinase C alpha) |
Relief mechanism |
|
Assay |
|
References
- Steinberg SF (2008) "Structural basis of protein kinase C isoform function", Physiological reviews, 88, 1341-78
- Sommese RF et al. (2017) "The Role of Regulatory Domains in Maintaining Autoinhibition in the Multidomain Kinase PKCα", The Journal of biological chemistry, 292, 2873-2880
- Pears CJ et al. (1990) "Mutagenesis of the pseudosubstrate site of protein kinase C leads to activation", European journal of biochemistry, 194, 89-94
- Smith MK et al. (1990) "Specificities of autoinhibitory domain peptides for four protein kinases. Implications for intact cell studies of protein kinase function", The Journal of biological chemistry, 265, 1837-40
- Slater SJ et al. (2002) "Regulation of PKC alpha activity by C1-C2 domain interactions", The Journal of biological chemistry, 277, 15277-85
- Jones AC et al. (2020) "Hypothesis: Unifying model of domain architecture for conventional and novel protein kinase C isozymes", IUBMB life, 72, 2584-2590
- Kirwan AF et al. (2003) "Inhibition of protein kinase C catalytic activity by additional regions within the human protein kinase Calpha-regulatory domain lying outside of the pseudosubstrate sequence", The Biochemical journal, 373, 571-81
- Huang X et al. (2003) "Crystal structure of an inactive Akt2 kinase domain", Structure (London, England : 1993), 11, 21-30
- Truebestein L et al. (2021) "Structure of autoinhibited Akt1 reveals mechanism of PIP(3)-mediated activation", Proceedings of the National Academy of Sciences of the United States of America, 118,
- Lučić I et al. (2018) "Conformational sampling of membranes by Akt controls its activation and inactivation", Proceedings of the National Academy of Sciences of the United States of America, 115, E3940-E3949
- Wagner J et al. (2009) "Discovery of 3-(1H-indol-3-yl)-4-[2-(4-methylpiperazin-1-yl)quinazolin-4-yl]pyrrole-2,5-dione (AEB071), a potent and selective inhibitor of protein kinase C isotypes", Journal of medicinal chemistry, 52, 6193-6
Autoinhibited structure

Activated structure
350 variants for P17252
| Variant ID(s) | Position | Change | Description | Diseaes Association | Provenance |
|---|---|---|---|---|---|
|
rs1169715895 CA400679737 |
2 | A>G | No |
ClinGen TOPMed |
|
|
rs571827499 CA293124407 |
4 | V>I | No |
ClinGen Ensembl |
|
|
CA400679764 rs879211098 |
6 | P>L | No |
ClinGen gnomAD |
|
|
rs879211098 CA293124419 |
6 | P>R | No |
ClinGen gnomAD |
|
|
rs761243704 CA8720584 |
7 | G>D | No |
ClinGen ExAC gnomAD |
|
|
rs1241363040 CA400679765 |
7 | G>S | No |
ClinGen gnomAD |
|
|
CA8720585 rs201024698 |
8 | N>S | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
CA8720586 rs754430626 |
9 | D>Y | No |
ClinGen ExAC gnomAD |
|
|
CA400679800 rs1567761628 |
12 | A>G | No |
ClinGen Ensembl |
|
|
CA400679807 rs1220774095 |
13 | S>F | No |
ClinGen gnomAD |
|
|
CA293124435 rs956503012 |
14 | Q>E | No |
ClinGen TOPMed gnomAD |
|
|
CA293124438 rs12944151 |
14 | Q>H | No |
ClinGen Ensembl |
|
|
CA400679810 rs1334216181 |
14 | Q>P | No |
ClinGen gnomAD |
|
|
CA8720589 rs370194402 |
15 | D>E | No |
ClinGen ESP ExAC gnomAD |
|
|
rs370194402 CA400679820 |
15 | D>E | No |
ClinGen ESP ExAC gnomAD |
|
|
rs758584716 CA8720590 |
16 | V>L | No |
ClinGen ExAC gnomAD |
|
|
rs747039638 CA8720592 |
17 | A>V | No |
ClinGen ExAC gnomAD |
|
|
rs542395606 CA8720594 |
18 | N>K | No |
ClinGen ExAC gnomAD |
|
|
rs755078848 CA8720593 |
18 | N>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400679840 rs1346778661 |
19 | R>H | No |
ClinGen gnomAD |
|
|
rs1264883870 CA400679854 |
21 | A>V | No |
ClinGen gnomAD |
|
|
rs1261479202 CA400679866 |
23 | K>R | No |
ClinGen gnomAD |
|
|
rs527574267 CA293124452 |
32 | H>N | No |
ClinGen Ensembl |
|
|
CA8720596 rs749195097 |
32 | H>Q | No |
ClinGen ExAC gnomAD |
|
|
CA400679930 rs749195097 |
32 | H>Q | No |
ClinGen ExAC gnomAD |
|
|
CA293124459 rs987622627 |
33 | E>Q | No |
ClinGen TOPMed |
|
|
rs1193055442 CA400679993 |
41 | A>S | No |
ClinGen gnomAD |
|
|
CA8720599 rs200801878 |
45 | K>R | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs1567761731 CA400680045 |
48 | T>I | No |
ClinGen Ensembl |
|
|
CA400680041 rs1321995232 |
48 | T>P | No |
ClinGen gnomAD |
|
|
rs760225427 CA8720601 |
50 | C>S | No |
ClinGen ExAC gnomAD |
|
|
CA400680071 rs1332665914 |
52 | H>N | No |
ClinGen gnomAD |
|
|
rs768288690 CA8720602 |
52 | H>R | No |
ClinGen ExAC gnomAD |
|
|
rs1229194759 CA400680101 |
56 | F>Y | No |
ClinGen gnomAD |
|
|
CA400680112 rs1330669334 |
57 | I>M | No |
ClinGen TOPMed |
|
|
rs1231145168 CA400680107 |
57 | I>V | No |
ClinGen TOPMed |
|
|
rs1208642777 CA400680140 COSM1239941 |
60 | F>L | oesophagus [Cosmic] | No |
ClinGen cosmic curated TOPMed |
|
CA293125379 rs376921936 |
68 | Q>H | No |
ClinGen ESP TOPMed |
|
|
rs1567858622 CA400801675 |
80 | E>A | No |
ClinGen Ensembl |
|
|
CA400801687 rs1168036317 |
81 | F>L | No |
ClinGen gnomAD |
|
|
rs1461673002 CA400801720 |
86 | C>* | No |
ClinGen gnomAD |
|
|
rs915754719 COSM4139760 CA293516493 |
89 | A>V | ovary [Cosmic] | No |
ClinGen cosmic curated Ensembl |
|
rs1450533796 CA400801743 |
90 | D>G | No |
ClinGen gnomAD |
|
|
COSM983139 rs758445868 CA8720653 |
94 | D>N | endometrium [Cosmic] | No |
ClinGen cosmic curated ExAC TOPMed gnomAD |
|
CA8720654 rs766268531 |
95 | T>S | No |
ClinGen ExAC gnomAD |
|
|
CA8720678 rs762002113 |
100 | S>N | No |
ClinGen ExAC gnomAD |
|
|
CA8720679 rs766356302 |
101 | K>R | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400685067 rs1165951448 |
103 | K>N | No |
ClinGen gnomAD |
|
|
rs1445801890 CA400685062 |
103 | K>R | No |
ClinGen gnomAD |
|
|
rs1355069162 CA400685083 |
105 | K>E | No |
ClinGen TOPMed |
|
|
CA293153097 rs201729185 |
106 | I>V | No |
ClinGen Ensembl |
|
|
rs267605006 CA293153101 |
107 | H>Y | No |
ClinGen Ensembl |
|
|
rs752262521 CA8720683 |
113 | T>A | No |
ClinGen ExAC gnomAD |
|
|
CA293153161 rs879027569 |
117 | H>R | No |
ClinGen TOPMed gnomAD |
|
|
CA293153167 rs201664310 |
122 | L>H | No |
ClinGen 1000Genomes |
|
|
CA293153169 rs1038606242 |
123 | Y>C | No |
ClinGen Ensembl |
|
|
CA400685309 rs1205570869 |
127 | H>R | No |
ClinGen gnomAD |
|
|
rs753287547 CA8720686 |
127 | H>Y | No |
ClinGen ExAC gnomAD |
|
|
rs1236116445 CA400685351 |
132 | C>W | No |
ClinGen TOPMed gnomAD |
|
|
rs1324531129 CA400685389 |
136 | D>N | No |
ClinGen gnomAD |
|
|
rs879077468 CA293155987 |
137 | M>T | No |
ClinGen Ensembl |
|
|
CA8720716 rs773494079 |
137 | M>V | No |
ClinGen ExAC gnomAD |
|
|
CA8720717 rs759379662 |
138 | N>D | No |
ClinGen ExAC gnomAD |
|
|
rs1567951979 CA400685412 |
139 | V>A | No |
ClinGen Ensembl |
|
|
CA8720718 rs771987815 |
139 | V>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8720720 rs760478437 |
141 | K>N | No |
ClinGen ExAC |
|
|
CA8720719 rs775294696 |
141 | K>R | No |
ClinGen ExAC gnomAD |
|
|
rs776243082 CA8720722 |
144 | V>I | No |
ClinGen ExAC gnomAD |
|
|
rs376472217 CA8720724 |
145 | I>M | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA8720723 rs761489847 |
145 | I>N | No |
ClinGen ExAC |
|
|
rs1459780030 CA400685450 |
145 | I>V | No |
ClinGen TOPMed |
|
|
rs750003387 CA8720725 |
146 | N>S | No |
ClinGen ExAC gnomAD |
|
|
CA400685461 rs1196245554 |
147 | V>I | No |
ClinGen TOPMed |
|
|
rs752033472 CA8720728 |
149 | S>R | No |
ClinGen ExAC gnomAD |
|
|
rs752033472 CA400685479 |
149 | S>R | No |
ClinGen ExAC gnomAD |
|
|
CA8720730 rs781720378 |
152 | G>R | No |
ClinGen ExAC gnomAD |
|
|
CA400685525 rs1567952072 |
156 | T>A | No |
ClinGen Ensembl |
|
|
CA400685543 rs1382662679 |
158 | K>R | No |
ClinGen TOPMed gnomAD |
|
|
rs1567952088 CA400685549 |
159 | R>T | No |
ClinGen Ensembl |
|
|
rs1303564138 COSM76052 CA400685561 |
161 | R>Q | ovary [Cosmic] | No |
ClinGen cosmic curated gnomAD |
|
CA293156044 rs372542565 |
162 | I>V | No |
ClinGen ESP TOPMed |
|
|
rs1407008672 CA400685574 |
163 | Y>F | No |
ClinGen gnomAD |
|
|
rs778155542 CA8720733 |
165 | K>N | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8720734 rs749323079 |
166 | A>T | No |
ClinGen ExAC gnomAD |
|
|
CA400685594 rs1263068379 |
166 | A>V | No |
ClinGen gnomAD |
|
|
rs1349191801 CA400685624 |
171 | E>Q | No |
ClinGen gnomAD |
|
|
CA400685632 rs1216473892 |
172 | K>E | No |
ClinGen TOPMed gnomAD |
|
|
rs376898012 CA8720735 |
174 | H>L | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs376898012 CA400685649 |
174 | H>R | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
COSM1710660 rs1567952142 CA400685647 |
174 | H>Y | skin [Cosmic] | No |
ClinGen cosmic curated Ensembl |
|
COSM163728 rs1462693086 CA400684183 |
178 | R>* | breast [Cosmic] | No |
ClinGen cosmic curated gnomAD |
|
rs151214307 CA293134860 |
178 | R>Q | No |
ClinGen ESP TOPMed gnomAD |
|
|
CA400684211 rs1446131290 |
182 | N>S | No |
ClinGen gnomAD |
|
|
rs776863583 CA8720756 |
182 | N>Y | No |
ClinGen ExAC gnomAD |
|
|
rs778898336 CA8720757 |
183 | L>R | No |
ClinGen ExAC gnomAD |
|
|
CA400684237 COSM1710661 rs1308387490 |
186 | M>I | skin [Cosmic] | No |
ClinGen cosmic curated gnomAD |
|
CA8720758 rs200732611 |
186 | M>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1037966573 CA293134886 |
201 | I>T | No |
ClinGen TOPMed |
|
|
rs776558609 CA293134894 |
203 | D>G | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1368594029 CA400684348 |
203 | D>H | No |
ClinGen gnomAD |
|
|
rs776558609 CA8720760 |
203 | D>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400684366 rs1343859163 |
205 | K>N | No |
ClinGen TOPMed |
|
|
rs1200620032 CA400684363 |
205 | K>R | No |
ClinGen TOPMed |
|
|
CA400684404 rs1459950139 |
210 | Q>R | No |
ClinGen gnomAD |
|
|
CA400684424 rs1411621502 |
213 | K>T | No |
ClinGen gnomAD |
|
|
CA400684438 rs1181146279 |
215 | I>N | No |
ClinGen gnomAD |
|
|
rs769603612 CA8720762 |
216 | R>C | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8720763 rs532000022 |
216 | R>H | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
rs140400644 CA8720764 |
217 | S>C | No |
ClinGen ESP ExAC |
|
|
rs759130548 CA8720767 |
221 | P>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8720769 rs753286297 |
222 | Q>H | No |
ClinGen ExAC gnomAD |
|
|
rs1428713498 CA400684503 |
225 | E>A | No |
ClinGen TOPMed |
|
|
CA400684500 rs1297560368 |
225 | E>Q | No |
ClinGen TOPMed |
|
|
rs761072166 CA293134929 |
228 | T>I | No |
ClinGen ExAC gnomAD |
|
|
rs761072166 CA8720770 |
228 | T>K | No |
ClinGen ExAC gnomAD |
|
|
rs1337976930 CA400684572 |
233 | P>R | No |
ClinGen gnomAD |
|
|
CA400684570 rs1360216746 |
233 | P>S | No |
ClinGen gnomAD |
|
|
rs1404643413 CA400684601 |
237 | D>G | No |
ClinGen TOPMed |
|
|
CA293135382 rs878902960 |
238 | R>* | No |
ClinGen gnomAD |
|
|
CA400684606 rs776118914 |
238 | R>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8720787 rs776118914 |
238 | R>Q | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8720788 rs761303069 |
239 | R>* | No |
ClinGen ExAC gnomAD |
|
|
rs199575835 CA8720790 |
242 | V>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs199575835 CA8720789 |
242 | V>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400684630 rs1318686404 |
243 | E>G | No |
ClinGen gnomAD |
|
|
CA293135404 rs879174883 |
247 | W>R | No |
ClinGen Ensembl |
|
|
CA8720792 rs1191887100 |
249 | R>Q | No |
ClinGen TOPMed |
|
|
rs749197302 CA293135405 |
252 | R>G | No |
ClinGen Ensembl |
|
|
CA8720795 rs750671800 |
254 | D>V | No |
ClinGen ExAC gnomAD |
|
|
rs1257897049 CA400684718 |
255 | F>L | No |
ClinGen TOPMed |
|
|
rs758455185 CA8720796 |
256 | M>V | No |
ClinGen ExAC gnomAD |
|
|
CA8720799 rs756067154 |
266 | L>V | No |
ClinGen ExAC gnomAD |
|
|
CA400684795 rs1231170984 |
267 | M>I | No |
ClinGen TOPMed |
|
|
rs1408759009 CA400684791 |
267 | M>L | No |
ClinGen TOPMed gnomAD |
|
|
rs748972010 CA8720801 |
269 | M>I | No |
ClinGen ExAC TOPMed |
|
|
rs770791840 CA8720802 |
270 | P>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs770791840 CA400684817 |
270 | P>Q | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400684825 rs1425686580 |
272 | S>C | No |
ClinGen gnomAD |
|
|
CA293135439 rs771675464 |
272 | S>R | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs372242332 CA8720804 |
272 | S>T | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs745511133 CA8720822 |
275 | Y>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs140607549 CA8720824 |
278 | L>F | No |
ClinGen ESP ExAC gnomAD |
|
|
CA400684901 rs1309379769 |
281 | E>K | No |
ClinGen gnomAD |
|
|
CA400684917 rs1196807485 |
283 | G>S | No |
ClinGen gnomAD |
|
|
rs748732162 CA8720828 |
288 | V>I | No |
ClinGen ExAC gnomAD |
|
|
CA8720829 rs770142713 |
289 | P>S | No |
ClinGen ExAC gnomAD |
|
|
rs773628505 CA8720830 |
290 | I>V | No |
ClinGen ExAC gnomAD |
|
|
CA400684977 rs1168175864 |
291 | P>L | No |
ClinGen TOPMed gnomAD |
|
|
CA293135771 rs121917733 |
294 | D>G | No |
ClinGen Ensembl |
|
|
CA8720835 rs774664493 |
299 | M>V | No |
ClinGen ExAC gnomAD |
|
|
rs1598875342 CA400685159 |
301 | L>F | No |
ClinGen Ensembl |
|
|
rs759487890 CA8720836 |
302 | R>K | No |
ClinGen ExAC gnomAD |
|
|
CA400685228 rs1598875352 |
305 | F>S | No |
ClinGen Ensembl |
|
|
rs1355720093 CA400685238 |
306 | E>K | No |
ClinGen TOPMed |
|
|
rs772038327 CA8720855 |
310 | L>V | No |
ClinGen ExAC gnomAD |
|
|
rs760849115 CA8720857 |
312 | P>R | No |
ClinGen ExAC gnomAD |
|
|
CA400685718 rs1220072648 |
312 | P>S | No |
ClinGen TOPMed |
|
|
rs1288619916 CA400685750 |
317 | V>I | No |
ClinGen gnomAD |
|
|
CA8720858 rs765196382 |
319 | S>N | No |
ClinGen ExAC gnomAD |
|
|
CA8720860 rs762784660 |
321 | S>P | No |
ClinGen ExAC gnomAD |
|
|
rs1196162859 CA400685790 |
323 | D>H | No |
ClinGen gnomAD |
|
|
CA8720863 rs754719581 |
324 | R>G | No |
ClinGen ExAC gnomAD |
|
|
rs1160172620 CA400685797 |
324 | R>K | No |
ClinGen gnomAD |
|
|
rs1269273559 CA400685806 |
325 | K>R | No |
ClinGen TOPMed |
|
|
CA400685811 rs1378321864 |
326 | Q>E | No |
ClinGen gnomAD |
|
|
rs1418829771 CA400685819 |
327 | P>A | No |
ClinGen TOPMed gnomAD |
|
|
CA8720864 rs780725433 |
327 | P>L | No |
ClinGen ExAC gnomAD |
|
|
CA8720865 rs752189270 |
328 | S>A | No |
ClinGen ExAC gnomAD |
|
|
CA8720866 rs149601883 |
329 | N>D | No |
ClinGen ESP ExAC gnomAD |
|
|
CA400685836 rs1330535595 |
330 | N>D | No |
ClinGen gnomAD |
|
|
CA400685845 rs1383892769 |
331 | L>V | No |
ClinGen Ensembl |
|
|
CA400685849 rs1303683158 |
332 | D>N | No |
ClinGen TOPMed |
|
|
rs749845868 CA8720868 |
333 | R>* | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8720869 rs376086959 |
333 | R>L | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA8720870 rs376086959 |
333 | R>Q | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1383145434 CA400685863 |
334 | V>A | No |
ClinGen gnomAD |
|
|
rs1274003131 CA400685875 |
336 | L>F | No |
ClinGen TOPMed |
|
|
rs148368351 CA8720872 |
337 | T>M | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
rs1489277782 CA400685904 |
340 | N>S | No |
ClinGen gnomAD |
|
|
rs773258598 CA8720876 |
343 | M>T | No |
ClinGen ExAC gnomAD |
|
|
CA8720877 rs373125854 |
344 | V>L | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA8720904 rs147347370 |
357 | D>N | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA8720905 rs765731873 |
360 | G>S | No |
ClinGen ExAC gnomAD |
|
|
CA8720906 rs139505198 |
365 | Y>F | No |
ClinGen ESP ExAC TOPMed |
|
|
rs1158533362 CA400686132 |
371 | K>N | No |
ClinGen gnomAD |
|
|
CA400686155 rs1321517380 |
375 | V>M | No |
ClinGen Ensembl |
|
|
CA400686167 rs879041600 |
376 | I>M | No |
ClinGen TOPMed |
|
|
rs1220047208 CA400686165 |
376 | I>T | No |
ClinGen gnomAD |
|
|
rs1417568507 CA400686176 |
378 | D>N | No |
ClinGen TOPMed |
|
|
rs748202197 CA8720914 |
381 | V>M | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs769786910 CA8720916 |
385 | M>K | No |
ClinGen ExAC gnomAD |
|
|
rs769786910 CA8720915 |
385 | M>T | No |
ClinGen ExAC gnomAD |
|
|
rs745835054 CA8720917 |
388 | K>Q | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400686256 rs1199673071 |
389 | R>* | No |
ClinGen TOPMed gnomAD |
|
|
COSM983153 CA8720918 rs561747335 |
389 | R>Q | endometrium [Cosmic] | No |
ClinGen cosmic curated 1000Genomes ExAC TOPMed gnomAD |
|
CA400686262 rs1260537657 |
390 | V>A | No |
ClinGen TOPMed |
|
|
rs775320348 CA8720919 |
390 | V>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA293167562 rs878948261 |
392 | A>V | No |
ClinGen TOPMed |
|
|
rs1568003918 CA400686285 |
394 | L>P | No |
ClinGen Ensembl |
|
|
CA8720920 rs760475739 |
395 | D>E | No |
ClinGen ExAC gnomAD |
|
|
rs912687125 CA293167581 |
395 | D>G | No |
ClinGen Ensembl |
|
|
rs1421635110 CA400686301 |
397 | P>T | No |
ClinGen gnomAD |
|
|
rs145121663 CA8720921 |
398 | P>L | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs145121663 CA8720922 |
398 | P>Q | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA400686309 rs1477516481 |
398 | P>S | No |
ClinGen gnomAD |
|
|
rs764698470 CA8720924 |
401 | T>M | No |
ClinGen ExAC gnomAD |
|
|
CA400686350 rs995374816 |
404 | H>Q | No |
ClinGen TOPMed gnomAD |
|
|
rs995374816 CA293167620 |
404 | H>Q | No |
ClinGen TOPMed gnomAD |
|
|
CA400686357 rs1339360556 |
406 | C>S | No |
ClinGen gnomAD |
|
|
rs1598908430 CA400686406 |
411 | D>Y | No |
ClinGen Ensembl |
|
|
rs1025381258 CA293169732 |
412 | R>Q | No |
ClinGen gnomAD |
|
|
CA400686436 rs768035157 |
415 | F>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8720948 rs541841621 |
416 | V>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs756351469 CA8720949 |
420 | V>I | No |
ClinGen ExAC gnomAD |
|
|
rs1331371121 COSM3764621 CA400686480 |
422 | G>S | central_nervous_system [Cosmic] | No |
ClinGen cosmic curated TOPMed |
|
CA8720953 rs531167467 |
426 | M>I | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
rs565487208 CA8720952 |
426 | M>T | No |
ClinGen 1000Genomes ExAC |
|
|
CA8720954 rs375513201 |
430 | Q>* | No |
ClinGen ESP ExAC gnomAD |
|
|
CA293169805 rs375513201 |
430 | Q>K | No |
ClinGen ESP ExAC gnomAD |
|
|
rs1598908491 CA400686556 |
433 | G>R | No |
ClinGen Ensembl |
|
|
CA400686578 rs1157234209 |
436 | K>E | No |
ClinGen gnomAD |
|
|
rs1396470503 CA400686591 |
437 | E>D | No |
ClinGen TOPMed |
|
|
CA293169815 rs990115740 |
437 | E>G | No |
ClinGen Ensembl |
|
|
rs780913123 CA8720956 |
440 | A>V | No |
ClinGen ExAC gnomAD |
|
|
CA8720975 rs747860021 |
443 | Y>* | No |
ClinGen ExAC gnomAD |
|
|
CA8720976 COSM212252 rs755962439 |
444 | A>V | endometrium breast [Cosmic] | No |
ClinGen cosmic curated ExAC gnomAD |
|
rs772638644 CA8720982 |
452 | F>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1175972657 CA400686699 |
452 | F>L | No |
ClinGen TOPMed gnomAD |
|
|
CA400686714 rs1278940098 |
454 | L>V | No |
ClinGen gnomAD |
|
|
CA8720984 rs760897668 |
457 | R>I | No |
ClinGen ExAC gnomAD |
|
|
rs916837548 CA293172148 |
458 | G>A | No |
ClinGen TOPMed gnomAD |
|
|
COSM1180088 CA8720998 rs745329705 |
469 | V>I | pancreas prostate [Cosmic] | No |
ClinGen cosmic curated ExAC gnomAD |
|
CA400686837 rs1568007965 |
470 | M>K | No |
ClinGen Ensembl |
|
|
rs771633891 CA8720999 |
470 | M>L | No |
ClinGen ExAC gnomAD |
|
|
rs1568007965 CA400686838 |
470 | M>T | No |
ClinGen Ensembl |
|
|
CA8721000 rs771633891 |
470 | M>V | No |
ClinGen ExAC gnomAD |
|
|
rs768894580 CA8721002 |
474 | E>K | No |
ClinGen ExAC gnomAD |
|
|
rs765405625 CA8721005 |
485 | C>G | No |
ClinGen ExAC |
|
|
rs1377657903 CA400686980 |
489 | M>I | No |
ClinGen gnomAD |
|
|
rs34406842 VAR_042303 CA8721007 |
489 | M>V | No |
ClinGen UniProt 1000Genomes ESP ExAC TOPMed dbSNP gnomAD |
|
|
rs766524625 CA8721008 |
490 | M>T | No |
ClinGen ExAC gnomAD |
|
|
CA8721009 rs752577272 |
491 | D>G | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs760726899 CA8721010 |
493 | V>I | No |
ClinGen ExAC gnomAD |
|
|
rs763954407 CA400687012 |
494 | T>M | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs763954407 CA8721011 |
494 | T>R | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs867898293 CA293172787 |
498 | F>I | No |
ClinGen Ensembl |
|
|
rs750145950 CA8721015 |
506 | A>P | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400687089 rs750145950 |
506 | A>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8721016 rs757811919 |
508 | E>V | No |
ClinGen ExAC gnomAD |
|
|
rs750091036 CA8721034 |
511 | A>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8721036 rs758127330 |
512 | Y>F | No |
ClinGen ExAC |
|
|
CA8721037 rs779586057 |
514 | P>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs929429787 CA293155223 |
516 | G>E | No |
ClinGen TOPMed gnomAD |
|
|
rs1400087303 CA400687168 |
516 | G>R | No |
ClinGen TOPMed |
|
|
CA400687182 rs1181432857 |
518 | S>P | No |
ClinGen gnomAD |
|
|
CA8721040 rs781649712 |
524 | Y>C | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs748695583 CA8721041 |
525 | G>S | No |
ClinGen ExAC gnomAD |
|
|
COSM561868 CA8721043 rs563946455 |
526 | V>I | lung [Cosmic] | No |
ClinGen cosmic curated ExAC TOPMed gnomAD |
|
CA400687253 rs1398642855 |
528 | L>F | No |
ClinGen gnomAD |
|
|
rs1568025885 CA400687274 |
531 | M>T | No |
ClinGen Ensembl |
|
|
CA293166651 rs926571782 |
542 | D>N | No |
ClinGen Ensembl |
|
|
rs1568034041 CA400687847 |
542 | D>V | No |
ClinGen Ensembl |
|
|
rs989781281 CA293166667 |
544 | D>N | No |
ClinGen gnomAD |
|
|
rs1482134884 CA400687865 |
545 | E>K | No |
ClinGen TOPMed gnomAD |
|
|
CA293166684 rs34133255 |
548 | Q>H | No |
ClinGen Ensembl |
|
|
CA293166702 rs145582519 |
550 | I>V | No |
ClinGen ESP TOPMed gnomAD |
|
|
rs200189588 CA293166713 |
554 | N>H | No |
ClinGen Ensembl |
|
|
CA293166731 rs945360674 |
554 | N>S | No |
ClinGen TOPMed gnomAD |
|
|
CA293166735 rs1041174047 |
555 | V>I | No |
ClinGen TOPMed gnomAD |
|
|
CA400687946 rs1340824301 |
556 | S>F | No |
ClinGen TOPMed |
|
|
rs758561582 CA400687954 |
557 | Y>* | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs932834899 CA293166755 |
558 | P>Q | No |
ClinGen Ensembl |
|
|
CA400687969 rs1308056551 |
560 | S>P | No |
ClinGen gnomAD |
|
|
CA8721067 rs775765715 |
562 | S>T | No |
ClinGen ExAC |
|
|
rs1205271820 CA400687991 |
563 | K>M | No |
ClinGen TOPMed gnomAD |
|
|
rs1205271820 CA400687990 |
563 | K>R | No |
ClinGen TOPMed gnomAD |
|
|
CA400688009 rs1174674611 |
566 | V>L | No |
ClinGen TOPMed |
|
|
CA8721068 rs6504459 VAR_050558 |
568 | V>I | No |
ClinGen UniProt 1000Genomes ESP ExAC TOPMed dbSNP gnomAD |
|
|
CA8721071 rs762789455 |
570 | K>Q | No |
ClinGen ExAC |
|
|
CA8721118 rs763386871 |
573 | M>I | No |
ClinGen ExAC gnomAD |
|
|
CA8721117 rs750987304 |
573 | M>L | No |
ClinGen ExAC gnomAD |
|
|
CA8721119 rs766918637 |
574 | T>I | No |
ClinGen ExAC gnomAD |
|
|
rs1598945323 CA400688082 |
575 | K>N | No |
ClinGen Ensembl |
|
|
rs1598945336 CA400688087 |
576 | H>P | No |
ClinGen Ensembl |
|
|
rs751820837 CA8721120 |
576 | H>Q | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400688086 rs1272799772 |
576 | H>Y | No |
ClinGen gnomAD |
|
|
CA8721122 rs755097684 |
578 | A>G | No |
ClinGen ExAC gnomAD |
|
|
CA8721121 rs755097684 |
578 | A>V | No |
ClinGen ExAC gnomAD |
|
|
CA8721123 rs752683507 |
579 | K>N | No |
ClinGen ExAC gnomAD |
|
|
CA400688107 rs752683507 |
579 | K>N | No |
ClinGen ExAC gnomAD |
|
|
CA400688109 rs1467859917 |
580 | R>W | No |
ClinGen TOPMed |
|
|
CA400688132 rs1193798167 |
584 | G>R | No |
ClinGen TOPMed gnomAD |
|
|
CA8721126 rs144172717 |
586 | E>D | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
rs144172717 CA8721125 |
586 | E>D | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA8721128 rs779879529 |
587 | G>R | No |
ClinGen ExAC gnomAD |
|
|
CA293168319 rs779879529 |
587 | G>W | No |
ClinGen ExAC gnomAD |
|
|
CA400688158 rs1598945398 |
588 | E>G | No |
ClinGen Ensembl |
|
|
rs1283176712 CA400688171 |
590 | D>N | No |
ClinGen TOPMed |
|
|
CA8721131 rs776376975 |
591 | V>M | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400688190 rs1304789263 |
593 | E>Q | No |
ClinGen TOPMed |
|
|
rs867890925 CA293168349 |
594 | H>N | No |
ClinGen gnomAD |
|
|
rs867890925 CA400688198 |
594 | H>Y | No |
ClinGen gnomAD |
|
|
CA400688216 rs769392914 |
596 | F>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400688224 rs1328249752 |
597 | F>L | No |
ClinGen gnomAD |
|
|
rs773823088 CA8721134 |
598 | R>W | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs763614166 CA8721135 |
599 | R>W | No |
ClinGen ExAC gnomAD |
|
|
CA293168384 rs923604011 |
601 | D>N | No |
ClinGen TOPMed |
|
|
CA8721136 rs767006638 |
602 | W>* | No |
ClinGen ExAC gnomAD |
|
|
rs1236969177 CA400688258 |
603 | E>K | No |
ClinGen gnomAD |
|
|
CA400688269 rs1157251571 |
604 | K>T | No |
ClinGen TOPMed |
|
|
rs759979805 CA8721138 |
607 | N>H | No |
ClinGen ExAC gnomAD |
|
|
CA293168388 rs765617766 |
608 | R>G | No |
ClinGen gnomAD |
|
|
CA8721139 COSM1263057 rs767590051 |
609 | E>Q | oesophagus [Cosmic] | No |
ClinGen cosmic curated ExAC gnomAD |
|
CA400688313 rs1568035475 |
610 | I>M | No |
ClinGen Ensembl |
|
|
CA400688328 rs1192456628 |
613 | P>T | No |
ClinGen gnomAD |
|
|
CA400688364 rs1191547383 |
618 | V>M | No |
ClinGen gnomAD |
|
|
CA293182340 rs369523075 |
619 | C>Y | No |
ClinGen ESP TOPMed |
|
|
CA293182351 rs879207427 |
621 | K>R | No |
ClinGen Ensembl |
|
|
rs1289928115 CA400688406 |
622 | G>* | No |
ClinGen TOPMed |
|
|
rs868351119 CA293182352 |
622 | G>E | No |
ClinGen Ensembl |
|
|
rs1598021084 CA400688450 |
628 | K>T | No |
ClinGen Ensembl |
|
|
rs755762168 CA8721171 |
629 | F>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs561355502 COSM1324893 CA8721173 |
632 | R>* | ovary [Cosmic] | No |
ClinGen cosmic curated 1000Genomes ExAC TOPMed gnomAD |
|
CA8721174 COSM1563701 rs140466753 |
632 | R>Q | large_intestine [Cosmic] | No |
ClinGen cosmic curated ESP ExAC TOPMed |
|
CA400688483 rs1197371682 |
633 | G>E | No |
ClinGen gnomAD |
|
|
RCV000957647 CA8721179 rs141376042 |
636 | V>I | No |
ClinGen ClinVar 1000Genomes ESP ExAC TOPMed dbSNP gnomAD |
|
|
CA8721182 rs761859483 |
645 | I>V | No |
ClinGen ExAC gnomAD |
|
|
CA400688572 rs1377169489 |
647 | N>S | No |
ClinGen gnomAD |
|
|
rs759461144 CA8721185 |
648 | I>M | No |
ClinGen ExAC gnomAD |
|
|
CA8721184 rs751445956 |
648 | I>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA8721183 rs765338275 |
648 | I>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs767363000 CA8721186 |
649 | D>E | No |
ClinGen ExAC gnomAD |
|
|
rs1412397562 CA400688594 |
650 | Q>H | No |
ClinGen gnomAD |
|
|
rs752497956 CA8721187 |
651 | S>F | No |
ClinGen ExAC gnomAD |
|
|
rs369070488 CA293182408 COSM983166 |
657 | S>L | endometrium [Cosmic] | No |
ClinGen cosmic curated ESP TOPMed gnomAD |
|
rs753589948 CA8721190 |
659 | V>A | No |
ClinGen ExAC gnomAD |
|
|
CA400688660 rs1258505958 |
660 | N>S | No |
ClinGen gnomAD |
|
|
rs778547161 CA8721192 |
661 | P>T | No |
ClinGen ExAC gnomAD |
|
|
rs745380001 CA8721193 |
662 | Q>R | No |
ClinGen ExAC gnomAD |
|
|
rs1173120345 CA400688703 |
666 | P>L | No |
ClinGen gnomAD |
|
|
CA8721195 rs373125445 |
667 | I>F | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA400688705 rs373125445 |
667 | I>V | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA8721197 rs747321782 |
668 | L>F | No |
ClinGen ExAC gnomAD |
|
|
CA400688713 rs1173461311 |
668 | L>S | No |
ClinGen gnomAD |
|
|
CA8721198 rs150241910 |
669 | Q>R | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1311799900 CA400688724 |
670 | S>G | No |
ClinGen gnomAD |
|
|
rs538946868 CA8721199 |
670 | S>N | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
CA400688732 rs1171007232 |
671 | A>S | No |
ClinGen TOPMed |
|
|
rs773277158 CA8721201 |
672 | V>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA400688742 rs1233714386 |
673 | V>R | No |
ClinGen gnomAD |
1 associated diseases with P17252
[MIM: 619841]: Chilton-Okur-Chung neurodevelopmental syndrome (CHOCNS)
A disorder characterized by developmental delay, intellectual disability, hypotonia, and structural brain abnormalities including cerebellar vermis hypoplasia and agenesis or hypoplasia of the corpus callosum. Most patients have behavioral abnormalities, including autism spectrum disorder, attention deficit and hyperactivity disorder, and aggression. About half of patients have dysmorphic facial features. Rare involvement of other organ systems may be present. . Note=The disease is caused by variants affecting the gene represented in this entry.
Without disease ID
- A disorder characterized by developmental delay, intellectual disability, hypotonia, and structural brain abnormalities including cerebellar vermis hypoplasia and agenesis or hypoplasia of the corpus callosum. Most patients have behavioral abnormalities, including autism spectrum disorder, attention deficit and hyperactivity disorder, and aggression. About half of patients have dysmorphic facial features. Rare involvement of other organ systems may be present. . Note=The disease is caused by variants affecting the gene represented in this entry.
15 regional properties for P17252
| Type | Name | Position | InterPro Accession |
|---|---|---|---|
| domain | CRIB domain | 1583 - 1618 | IPR000095 |
| domain | Protein kinase domain | 76 - 342 | IPR000719 |
| domain | AGC-kinase, C-terminal | 343 - 413 | IPR000961 |
| domain | Citron homology (CNH) domain | 1240 - 1519 | IPR001180 |
| domain | Pleckstrin homology domain | 1095 - 1216 | IPR001849 |
| domain | Protein kinase C-like, phorbol ester/diacylglycerol-binding domain | 1025 - 1076 | IPR002219 |
| active_site | Serine/threonine-protein kinase, active site | 196 - 208 | IPR008271 |
| domain | Myotonic dystrophy protein kinase, coiled coil | 878 - 939 | IPR014930 |
| binding_site | Protein kinase, ATP binding site | 82 - 105 | IPR017441 |
| domain | Diacylglycerol/phorbol-ester binding | 1023 - 1037 | IPR020454-1 |
| domain | Diacylglycerol/phorbol-ester binding | 1039 - 1048 | IPR020454-2 |
| domain | Diacylglycerol/phorbol-ester binding | 1052 - 1063 | IPR020454-3 |
| domain | Diacylglycerol/phorbol-ester binding | 1064 - 1076 | IPR020454-4 |
| domain | KELK-motif containing domain | 528 - 606 | IPR031597 |
| domain | Serine/threonine-protein kinase MRCK beta, catalytic domain | 3 - 411 | IPR042718 |
Functions
10 GO annotations of cellular component
| Name | Definition |
|---|---|
| alphav-beta3 integrin-PKCalpha complex | A protein complex that consists of an alphav-beta3 integrin complex bound to protein kinase C alpha. |
| cytoplasm | The contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| cytosol | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| endoplasmic reticulum | The irregular network of unit membranes, visible only by electron microscopy, that occurs in the cytoplasm of many eukaryotic cells. The membranes form a complex meshwork of tubular channels, which are often expanded into slitlike cavities called cisternae. The ER takes two forms, rough (or granular), with ribosomes adhering to the outer surface, and smooth (with no ribosomes attached). |
| extracellular exosome | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| mitochondrial membrane | Either of the lipid bilayers that surround the mitochondrion and form the mitochondrial envelope. |
| mitochondrion | A semiautonomous, self replicating organelle that occurs in varying numbers, shapes, and sizes in the cytoplasm of virtually all eukaryotic cells. It is notably the site of tissue respiration. |
| nucleoplasm | That part of the nuclear content other than the chromosomes or the nucleolus. |
| perinuclear region of cytoplasm | Cytoplasm situated near, or occurring around, the nucleus. |
| plasma membrane | The membrane surrounding a cell that separates the cell from its external environment. It consists of a phospholipid bilayer and associated proteins. |
11 GO annotations of molecular function
| Name | Definition |
|---|---|
| ATP binding | Binding to ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| calcium-dependent protein kinase C activity | Calcium-dependent catalysis of the reaction: ATP + a protein = ADP + a phosphoprotein. |
| enzyme binding | Binding to an enzyme, a protein with catalytic activity. |
| histone kinase activity (H3-T6 specific) | Catalysis of the transfer of a phosphate group to the threonine-6 residue of the N-terminal tail of histone H3. |
| integrin binding | Binding to an integrin. |
| protein kinase activity | Catalysis of the phosphorylation of an amino acid residue in a protein, usually according to the reaction: a protein + ATP = a phosphoprotein + ADP. |
| protein kinase C activity | Catalysis of the reaction: ATP + a protein = ADP + a phosphoprotein. This reaction requires diacylglycerol. |
| protein serine kinase activity | Catalysis of the reactions: ATP + protein serine = ADP + protein serine phosphate. |
| protein serine/threonine kinase activity | Catalysis of the reactions: ATP + protein serine = ADP + protein serine phosphate, and ATP + protein threonine = ADP + protein threonine phosphate. |
| protein serine/threonine/tyrosine kinase activity | Catalysis of the reactions: ATP + a protein serine = ADP + protein serine phosphate; ATP + a protein threonine = ADP + protein threonine phosphate; and ATP + a protein tyrosine = ADP + protein tyrosine phosphate. |
| zinc ion binding | Binding to a zinc ion (Zn). |
28 GO annotations of biological process
| Name | Definition |
|---|---|
| angiogenesis | Blood vessel formation when new vessels emerge from the proliferation of pre-existing blood vessels. |
| apoptotic signaling pathway | The series of molecular signals which triggers the apoptotic death of a cell. The pathway starts with reception of a signal, and ends when the execution phase of apoptosis is triggered. |
| cell adhesion | The attachment of a cell, either to another cell or to an underlying substrate such as the extracellular matrix, via cell adhesion molecules. |
| desmosome assembly | A cellular process that results in the aggregation, arrangement and bonding together of a set of components to form a desmosome. A desmosome is a patch-like intercellular junction found in vertebrate tissues, consisting of parallel zones of two cell membranes, separated by an space of 25-35 nm, and having dense fibrillar plaques in the subjacent cytoplasm. |
| histone H3-T6 phosphorylation | OBSOLETE. The modification of histone H3 by the addition of an phosphate group to a threonine residue at position 6 of the histone. |
| intracellular signal transduction | The process in which a signal is passed on to downstream components within the cell, which become activated themselves to further propagate the signal and finally trigger a change in the function or state of the cell. |
| mitotic nuclear membrane disassembly | The mitotic cell cycle process in which the controlled partial or complete breakdown of the nuclear membranes during occurs during mitosis. |
| negative regulation of glial cell apoptotic process | Any process that stops, prevents, or reduces the frequency, rate, or extent of glial cell apoptotic process. |
| peptidyl-serine phosphorylation | The phosphorylation of peptidyl-serine to form peptidyl-O-phospho-L-serine. |
| peptidyl-threonine phosphorylation | The phosphorylation of peptidyl-threonine to form peptidyl-O-phospho-L-threonine. |
| positive regulation of adenylate cyclase-activating G protein-coupled receptor signaling pathway | Any process that activates or increases the frequency, rate or extent of an adenylate cyclase-activating G protein-coupled receptor signaling pathway. |
| positive regulation of angiogenesis | Any process that activates or increases angiogenesis. |
| positive regulation of blood vessel endothelial cell migration | Any process that activates or increases the frequency, rate or extent of the migration of the endothelial cells of blood vessels. |
| positive regulation of bone resorption | Any process that activates or increases the frequency, rate or extent of bone resorption. |
| positive regulation of cardiac muscle hypertrophy | Any process that increases the rate, frequency or extent of the enlargement or overgrowth of all or part of the heart due to an increase in size (not length) of individual cardiac muscle fibers, without cell division. |
| positive regulation of cell adhesion | Any process that activates or increases the frequency, rate or extent of cell adhesion. |
| positive regulation of cell migration | Any process that activates or increases the frequency, rate or extent of cell migration. |
| positive regulation of dense core granule biogenesis | Any process that activates or increases the frequency, rate or extent of dense core granule biogenesis. |
| positive regulation of endothelial cell migration | Any process that increases the rate, frequency, or extent of the orderly movement of an endothelial cell into the extracellular matrix to form an endothelium. |
| positive regulation of endothelial cell proliferation | Any process that activates or increases the rate or extent of endothelial cell proliferation. |
| positive regulation of ERK1 and ERK2 cascade | Any process that activates or increases the frequency, rate or extent of signal transduction mediated by the ERK1 and ERK2 cascade. |
| positive regulation of lipopolysaccharide-mediated signaling pathway | Any process that activates or increases the frequency, rate or extent of signaling in response to detection of lipopolysaccharide. |
| positive regulation of macrophage differentiation | Any process that activates or increases the frequency, rate or extent of macrophage differentiation. |
| positive regulation of mitotic cell cycle | Any process that activates or increases the rate or extent of progression through the mitotic cell cycle. |
| protein phosphorylation | The process of introducing a phosphate group on to a protein. |
| regulation of mRNA stability | Any process that modulates the propensity of mRNA molecules to degradation. Includes processes that both stabilize and destabilize mRNAs. |
| regulation of platelet aggregation | Any process that modulates the rate, frequency or extent of platelet aggregation. Platelet aggregation is the adhesion of one platelet to one or more other platelets via adhesion molecules. |
| response to interleukin-1 | Any process that results in a change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of an interleukin-1 stimulus. |
40 homologous proteins in AiPD
| UniProt AC | Gene Name | Protein Name | Species | Evidence Code |
|---|---|---|---|---|
| P24583 | PKC1 | Protein kinase C-like 1 | Saccharomyces cerevisiae (strain ATCC 204508 / S288c) (Baker's yeast) | SS |
| P05128 | PRKCG | Protein kinase C gamma type | Bos taurus (Bovine) | SS |
| P05126 | PRKCB | Protein kinase C beta type | Bos taurus (Bovine) | SS |
| P04409 | PRKCA | Protein kinase C alpha type | Bos taurus (Bovine) | EV SS |
| P13677 | inaC | Protein kinase C, eye isozyme | Drosophila melanogaster (Fruit fly) | SS |
| P05130 | Pkc53E | Protein kinase C, brain isozyme | Drosophila melanogaster (Fruit fly) | SS |
| O15530 | PDPK1 | 3-phosphoinositide-dependent protein kinase 1 | Homo sapiens (Human) | EV |
| Q05513 | PRKCZ | Protein kinase C zeta type | Homo sapiens (Human) | SS |
| P41743 | PRKCI | Protein kinase C iota type | Homo sapiens (Human) | EV |
| Q16512 | PKN1 | Serine/threonine-protein kinase N1 | Homo sapiens (Human) | EV |
| Q6P5Z2 | PKN3 | Serine/threonine-protein kinase N3 | Homo sapiens (Human) | SS |
| Q16513 | PKN2 | Serine/threonine-protein kinase N2 | Homo sapiens (Human) | EV |
| P24723 | PRKCH | Protein kinase C eta type | Homo sapiens (Human) | SS |
| Q02156 | PRKCE | Protein kinase C epsilon type | Homo sapiens (Human) | SS |
| Q04759 | PRKCQ | Protein kinase C theta type | Homo sapiens (Human) | PR |
| Q05655 | PRKCD | Protein kinase C delta type | Homo sapiens (Human) | SS |
| P05129 | PRKCG | Protein kinase C gamma type | Homo sapiens (Human) | SS |
| P05771 | PRKCB | Protein kinase C beta type | Homo sapiens (Human) | SS |
| P31751 | AKT2 | RAC-beta serine/threonine-protein kinase | Homo sapiens (Human) | EV SS |
| P31749 | AKT1 | RAC-alpha serine/threonine-protein kinase | Homo sapiens (Human) | EV |
| Q9Y243 | AKT3 | RAC-gamma serine/threonine-protein kinase | Homo sapiens (Human) | SS |
| Q96BR1 | SGK3 | Serine/threonine-protein kinase Sgk3 | Homo sapiens (Human) | SS |
| Q9HBY8 | SGK2 | Serine/threonine-protein kinase Sgk2 | Homo sapiens (Human) | SS |
| O00141 | SGK1 | Serine/threonine-protein kinase Sgk1 | Homo sapiens (Human) | PR |
| Q15208 | STK38 | Serine/threonine-protein kinase 38 | Homo sapiens (Human) | EV |
| Q9Y2H1 | STK38L | Serine/threonine-protein kinase 38-like | Homo sapiens (Human) | EV |
| Q6A1A2 | PDPK2P | Putative 3-phosphoinositide-dependent protein kinase 2 | Homo sapiens (Human) | PR |
| P63318 | Prkcg | Protein kinase C gamma type | Mus musculus (Mouse) | SS |
| P68404 | Prkcb | Protein kinase C beta type | Mus musculus (Mouse) | SS |
| P20444 | Prkca | Protein kinase C alpha type | Mus musculus (Mouse) | SS |
| P16054 | Prkce | Protein kinase C epsilon type | Mus musculus (Mouse) | PR |
| P23298 | Prkch | Protein kinase C eta type | Mus musculus (Mouse) | PR |
| P68403 | Prkcb | Protein kinase C beta type | Rattus norvegicus (Rat) | SS |
| P63319 | Prkcg | Protein kinase C gamma type | Rattus norvegicus (Rat) | SS |
| Q64617 | Prkch | Protein kinase C eta type | Rattus norvegicus (Rat) | PR |
| P05696 | Prkca | Protein kinase C alpha type | Rattus norvegicus (Rat) | SS |
| P90980 | pkc-2 | Protein kinase C-like 2 | Caenorhabditis elegans | SS |
| Q9SUA3 | D6PKL1 | Serine/threonine-protein kinase D6PKL1 | Arabidopsis thaliana (Mouse-ear cress) | PR |
| A8KBH6 | prkcb | Protein kinase C beta type | Xenopus tropicalis (Western clawed frog) (Silurana tropicalis) | SS |
| Q7SY24 | prkcbb | Protein kinase C beta type | Danio rerio (Zebrafish) (Brachydanio rerio) | SS |
| 10 | 20 | 30 | 40 | 50 | 60 |
| MADVFPGNDS | TASQDVANRF | ARKGALRQKN | VHEVKDHKFI | ARFFKQPTFC | SHCTDFIWGF |
| 70 | 80 | 90 | 100 | 110 | 120 |
| GKQGFQCQVC | CFVVHKRCHE | FVTFSCPGAD | KGPDTDDPRS | KHKFKIHTYG | SPTFCDHCGS |
| 130 | 140 | 150 | 160 | 170 | 180 |
| LLYGLIHQGM | KCDTCDMNVH | KQCVINVPSL | CGMDHTEKRG | RIYLKAEVAD | EKLHVTVRDA |
| 190 | 200 | 210 | 220 | 230 | 240 |
| KNLIPMDPNG | LSDPYVKLKL | IPDPKNESKQ | KTKTIRSTLN | PQWNESFTFK | LKPSDKDRRL |
| 250 | 260 | 270 | 280 | 290 | 300 |
| SVEIWDWDRT | TRNDFMGSLS | FGVSELMKMP | ASGWYKLLNQ | EEGEYYNVPI | PEGDEEGNME |
| 310 | 320 | 330 | 340 | 350 | 360 |
| LRQKFEKAKL | GPAGNKVISP | SEDRKQPSNN | LDRVKLTDFN | FLMVLGKGSF | GKVMLADRKG |
| 370 | 380 | 390 | 400 | 410 | 420 |
| TEELYAIKIL | KKDVVIQDDD | VECTMVEKRV | LALLDKPPFL | TQLHSCFQTV | DRLYFVMEYV |
| 430 | 440 | 450 | 460 | 470 | 480 |
| NGGDLMYHIQ | QVGKFKEPQA | VFYAAEISIG | LFFLHKRGII | YRDLKLDNVM | LDSEGHIKIA |
| 490 | 500 | 510 | 520 | 530 | 540 |
| DFGMCKEHMM | DGVTTRTFCG | TPDYIAPEII | AYQPYGKSVD | WWAYGVLLYE | MLAGQPPFDG |
| 550 | 560 | 570 | 580 | 590 | 600 |
| EDEDELFQSI | MEHNVSYPKS | LSKEAVSVCK | GLMTKHPAKR | LGCGPEGERD | VREHAFFRRI |
| 610 | 620 | 630 | 640 | 650 | 660 |
| DWEKLENREI | QPPFKPKVCG | KGAENFDKFF | TRGQPVLTPP | DQLVIANIDQ | SDFEGFSYVN |
| 670 | |||||
| PQFVHPILQS | AV |