P15036
Gene name |
ETS2 |
Protein name |
Protein C-ets-2 |
Names |
|
Species |
Homo sapiens (Human) |
KEGG Pathway |
hsa:2114 |
EC number |
|
Protein Class |
ETS (PTHR11849) |
Descriptions
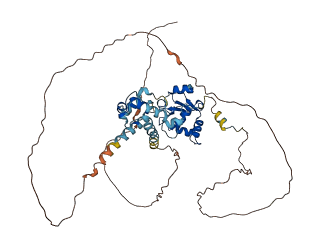
ETS2 is a member of the Ets family of DNA binding transcription factors. It is subject to multiple levels of regulation of their DNA binding and transactivation properties. ETS2 autoinhibition is mediated by the packing of helices within the N-terminal inhibitory domain and C-terminal inhibitory domain onto helix H1 of the ETS domain.
Autoinhibitory domains (AIDs)
Target domain |
359-439 (Helix H1 of ETS domain) |
Relief mechanism |
Others |
Assay |
Deletion assay, Structural analysis |
Target domain |
359-439 (Helix H1 of ETS domain) |
Relief mechanism |
Others |
Assay |
Deletion assay, Structural analysis |
Accessory elements
No accessory elements
References
- Newman JA et al. (2015) "Structural insights into the autoregulation and cooperativity of the human transcription factor Ets-2", The Journal of biological chemistry, 290, 8539-49
- Basuyaux JP et al. (1997) "The Ets transcription factors interact with each other and with the c-Fos/c-Jun complex via distinct protein domains in a DNA-dependent and -independent manner", The Journal of biological chemistry, 272, 26188-95
Autoinhibited structure

Activated structure
3 structures for P15036
| Entry ID | Method | Resolution | Chain | Position | Source |
|---|---|---|---|---|---|
| 4BQA | X-ray | 250 A | A/D/G | 325-464 | PDB |
| 4MHV | X-ray | 245 A | A/B | 76-170 | PDB |
| AF-P15036-F1 | Predicted | AlphaFoldDB |
281 variants for P15036
| Variant ID(s) | Position | Change | Description | Diseaes Association | Provenance |
|---|---|---|---|---|---|
|
rs915550106 CA320507422 |
5 | G>R | No |
ClinGen TOPMed gnomAD |
|
|
CA10025372 rs756583173 |
8 | N>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA10025374 rs115148137 |
15 | V>L | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs115148137 CA10025375 |
15 | V>M | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA10025376 rs779037031 |
16 | A>D | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA10025377 rs745988316 |
17 | N>H | No |
ClinGen ExAC gnomAD |
|
|
CA10025378 rs150592938 |
17 | N>S | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA320507437 rs908247678 |
18 | S>G | No |
ClinGen TOPMed |
|
|
CA10025406 rs139909964 |
25 | R>C | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs771933020 CA10025407 |
25 | R>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA10025408 rs143407258 |
27 | P>L | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA409943053 rs143407258 |
27 | P>Q | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA409943060 rs1288008218 |
28 | A>V | No |
ClinGen TOPMed |
|
|
rs995949573 CA320508506 |
31 | T>N | No |
ClinGen Ensembl |
|
|
CA409943098 rs1375831059 |
34 | G>R | No |
ClinGen gnomAD |
|
|
rs1204664395 CA409943107 |
35 | S>Y | No |
ClinGen gnomAD |
|
|
rs1466435861 CA409943113 |
36 | L>P | No |
ClinGen gnomAD |
|
|
rs754290340 CA10025412 |
38 | A>P | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA320508521 rs1001125602 |
39 | V>D | No |
ClinGen TOPMed gnomAD |
|
|
CA409943163 rs1362016995 |
44 | N>I | No |
ClinGen TOPMed gnomAD |
|
|
rs1362016995 CA409943162 |
44 | N>S | No |
ClinGen TOPMed gnomAD |
|
|
CA409943169 rs1282333788 |
45 | E>G | No |
ClinGen gnomAD |
|
|
CA409943178 rs1452924036 |
46 | E>G | No |
ClinGen gnomAD |
|
|
CA320508529 rs1050170011 |
47 | Q>E | No |
ClinGen Ensembl |
|
|
rs758609091 CA10025417 |
51 | E>Q | No |
ClinGen ExAC gnomAD |
|
|
rs1438333285 CA409943281 |
56 | L>V | No |
ClinGen gnomAD |
|
|
CA320508537 rs868010226 |
58 | S>F | No |
ClinGen Ensembl |
|
|
rs1430466105 CA409943336 |
60 | S>C | No |
ClinGen TOPMed |
|
|
rs1324799279 CA409943346 |
61 | H>R | No |
ClinGen TOPMed gnomAD |
|
|
rs780267734 CA10025418 |
62 | D>N | No |
ClinGen ExAC gnomAD |
|
|
rs1280673132 CA409943885 |
63 | S>F | No |
ClinGen gnomAD |
|
|
RCV000968784 rs34373350 CA10025437 |
64 | A>T | No |
ClinGen ClinVar 1000Genomes ESP ExAC TOPMed dbSNP gnomAD |
|
|
CA10025439 rs781489122 |
65 | N>K | No |
ClinGen ExAC gnomAD |
|
|
rs755229059 CA10025438 |
65 | N>S | No |
ClinGen ExAC gnomAD |
|
|
CA409943953 rs1205833064 |
68 | L>F | No |
ClinGen gnomAD |
|
|
CA10025441 rs756017903 |
69 | P>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA10025442 rs777697990 |
73 | P>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA409944032 rs1187443602 |
74 | C>G | No |
ClinGen TOPMed |
|
|
rs539702108 CA10025445 |
79 | M>I | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA409944153 rs1353159322 |
82 | A>V | No |
ClinGen gnomAD |
|
|
CA10025447 rs144867115 |
88 | S>R | No |
ClinGen ESP ExAC TOPMed |
|
|
rs114481523 CA10025448 |
91 | K>R | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA10025450 rs149038175 |
95 | R>Q | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs760122401 CA10025449 |
95 | R>W | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs930149085 CA320508930 |
96 | R>C | No |
ClinGen gnomAD |
|
|
rs535308565 CA10025451 |
96 | R>H | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs535308565 CA10025452 |
96 | R>L | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs1447801871 CA409944383 |
98 | G>C | No |
ClinGen TOPMed gnomAD |
|
|
CA10025453 rs766816665 |
98 | G>D | No |
ClinGen ExAC gnomAD |
|
|
rs1341661839 CA409944430 |
101 | K>N | No |
ClinGen gnomAD |
|
|
rs752915999 CA10025475 |
102 | N>K | No |
ClinGen ExAC gnomAD |
|
|
CA409944505 rs767881783 |
102 | N>S | No |
ClinGen ExAC gnomAD |
|
|
rs767881783 CA10025474 |
102 | N>T | No |
ClinGen ExAC gnomAD |
|
|
CA409944623 rs1426522494 |
110 | Q>H | No |
ClinGen TOPMed gnomAD |
|
|
rs760783079 CA10025476 |
112 | C>G | No |
ClinGen ExAC gnomAD |
|
|
CA409944688 rs1227099494 |
114 | W>* | No |
ClinGen gnomAD |
|
|
rs753854772 CA10025478 |
115 | L>F | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs78391361 CA10025479 |
116 | L>F | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs78391361 CA10025480 |
116 | L>V | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA10025482 rs758150519 |
117 | W>S | No |
ClinGen ExAC |
|
|
CA409944734 rs1374696251 |
118 | A>S | No |
ClinGen TOPMed |
|
|
rs746724832 CA10025484 |
119 | T>P | No |
ClinGen ExAC |
|
|
CA409944743 rs780811710 |
120 | N>D | No |
ClinGen ExAC gnomAD |
|
|
CA10025486 rs780811710 |
120 | N>H | No |
ClinGen ExAC gnomAD |
|
|
CA10025487 rs201321686 |
120 | N>S | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
rs1267005843 CA409944768 |
123 | S>N | No |
ClinGen gnomAD |
|
|
rs774957702 CA10025489 |
125 | V>E | No |
ClinGen ExAC |
|
|
rs773376571 CA409944789 |
126 | N>K | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs772611992 CA10025491 |
127 | V>M | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA10025492 rs775683010 |
128 | N>H | No |
ClinGen ExAC gnomAD |
|
|
rs775683010 CA10025493 |
128 | N>Y | No |
ClinGen ExAC gnomAD |
|
|
CA10025494 rs764212435 |
130 | Q>R | No |
ClinGen ExAC gnomAD |
|
|
CA409944820 rs776789283 |
131 | R>S | No |
ClinGen ExAC gnomAD |
|
|
CA10025496 rs761816863 |
132 | F>I | No |
ClinGen ExAC gnomAD |
|
|
CA10025498 rs201897945 |
133 | G>S | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1417359876 CA409944861 |
137 | Q>R | No |
ClinGen TOPMed |
|
|
CA320509148 rs996382296 |
138 | M>I | No |
ClinGen TOPMed |
|
|
CA409944866 rs1392590037 |
138 | M>L | No |
ClinGen gnomAD |
|
|
CA10025502 rs754672212 |
140 | C>Y | No |
ClinGen ExAC gnomAD |
|
|
CA10025503 rs780641610 |
143 | G>S | No |
ClinGen ExAC gnomAD |
|
|
rs888988500 CA320509165 |
143 | G>V | No |
ClinGen Ensembl |
|
|
rs1803557 CA320509166 |
145 | E>V | No |
ClinGen Ensembl |
|
|
rs755635528 COSM3713443 COSM3713442 CA10025505 |
146 | R>C | upper_aerodigestive_tract [Cosmic] | No |
ClinGen cosmic curated ExAC TOPMed gnomAD |
|
CA409944919 rs1350625148 |
146 | R>H | No |
ClinGen TOPMed gnomAD |
|
|
rs1229721854 CA409944932 |
148 | L>Q | No |
ClinGen gnomAD |
|
|
CA10025509 rs147754962 |
150 | L>V | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA10025510 rs747282020 |
151 | A>T | No |
ClinGen ExAC gnomAD |
|
|
rs142517222 CA10025511 |
154 | F>L | No |
ClinGen ESP ExAC |
|
|
CA10025512 rs776679730 |
167 | I>N | No |
ClinGen ExAC gnomAD |
|
|
CA10025528 rs747434496 |
172 | E>D | No |
ClinGen ExAC gnomAD |
|
|
rs1195681924 CA409945335 |
174 | T>R | No |
ClinGen TOPMed |
|
|
CA409945349 rs1433767109 |
176 | D>G | No |
ClinGen gnomAD |
|
|
CA409945345 rs1176734752 |
176 | D>N | No |
ClinGen TOPMed |
|
|
rs768857570 CA10025530 |
178 | Y>C | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA409945380 rs1273946656 |
180 | E>G | No |
ClinGen gnomAD |
|
|
CA409945394 rs1326047456 |
182 | S>A | No |
ClinGen TOPMed |
|
|
CA409945397 rs1344734147 |
182 | S>L | No |
ClinGen gnomAD |
|
|
CA409945419 rs1229446249 |
186 | S>P | No |
ClinGen TOPMed gnomAD |
|
|
CA409945425 rs372145357 |
187 | V>F | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA10025532 rs372145357 |
187 | V>I | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1271400216 CA409945439 |
189 | H>R | No |
ClinGen TOPMed |
|
|
rs1324322890 CA409945465 |
192 | N>K | No |
ClinGen gnomAD |
|
|
CA409945470 rs1433831363 |
193 | S>N | No |
ClinGen TOPMed gnomAD |
|
|
CA409945484 rs1343317130 |
195 | T>A | No |
ClinGen gnomAD |
|
|
rs772028653 CA10025557 |
197 | G>D | No |
ClinGen ExAC gnomAD |
|
|
rs769999489 CA10025534 |
197 | G>S | No |
ClinGen ExAC gnomAD |
|
|
rs369614292 CA320510402 |
201 | E>D | No |
ClinGen ESP gnomAD |
|
|
rs775434582 CA409945985 |
203 | A>E | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs775434582 CA10025558 |
203 | A>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA409946001 rs1409520740 |
204 | P>L | No |
ClinGen gnomAD |
|
|
rs763874169 CA10025560 |
205 | Y>C | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs763874169 CA320510408 |
205 | Y>F | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA320510421 rs981053782 |
207 | M>I | No |
ClinGen gnomAD |
|
|
CA320510411 rs969951821 |
207 | M>T | No |
ClinGen gnomAD |
|
|
CA409946075 rs1387898672 |
209 | T>I | No |
ClinGen gnomAD |
|
|
rs1601430715 CA409946118 |
212 | Y>S | No |
ClinGen Ensembl |
|
|
rs753494319 CA10025562 |
213 | P>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA10025561 rs753494319 |
213 | P>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA10025565 rs755496148 |
214 | K>E | No |
ClinGen ExAC gnomAD |
|
|
rs552586832 CA10025566 |
214 | K>R | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA409946154 rs1283977667 |
215 | G>R | No |
ClinGen TOPMed |
|
|
rs1365789879 CA409946174 |
216 | G>A | No |
ClinGen TOPMed |
|
|
CA10025568 rs115908228 COSM94254 |
216 | G>S | breast [Cosmic] | No |
ClinGen cosmic curated 1000Genomes ExAC gnomAD |
|
rs61735785 RCV000961092 CA10025569 |
217 | L>I | No |
ClinGen ClinVar 1000Genomes ESP ExAC TOPMed dbSNP gnomAD |
|
|
rs114460001 CA10025570 |
218 | L>R | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs771176252 CA10025571 |
219 | D>G | No |
ClinGen ExAC gnomAD |
|
|
CA409946261 rs1182274965 |
221 | M>I | No |
ClinGen gnomAD |
|
|
CA10025572 rs778912960 |
221 | M>V | No |
ClinGen ExAC gnomAD |
|
|
CA10025573 rs115297166 |
222 | C>F | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
CA10025575 rs114562289 |
223 | P>L | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA409946283 rs771905336 |
223 | P>S | No |
ClinGen ExAC gnomAD |
|
|
rs771905336 CA10025574 |
223 | P>T | No |
ClinGen ExAC gnomAD |
|
|
COSM371865 rs1349030537 CA409946298 |
224 | A>S | lung [Cosmic] | No |
ClinGen cosmic curated gnomAD |
|
CA409946347 rs1457151046 |
228 | S>G | No |
ClinGen TOPMed |
|
|
CA409946353 rs1601430826 |
228 | S>I | No |
ClinGen Ensembl |
|
|
rs577157851 CA10025578 |
229 | V>I | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA10025579 rs577157851 |
229 | V>L | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA320510465 rs372641031 |
230 | L>F | No |
ClinGen ESP gnomAD |
|
|
CA409946376 rs1358536335 |
230 | L>P | No |
ClinGen gnomAD |
|
|
CA10025580 rs764929763 |
232 | S>F | No |
ClinGen ExAC gnomAD |
|
|
CA409946412 rs1476307789 |
233 | E>G | No |
ClinGen TOPMed |
|
|
CA10025581 rs539828835 |
233 | E>Q | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs558527007 CA10025582 |
234 | Q>E | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs371568403 CA409946429 |
235 | E>K | No |
ClinGen TOPMed |
|
|
rs371568403 CA320510477 |
235 | E>Q | No |
ClinGen TOPMed |
|
|
CA320510485 rs777554249 |
238 | M>I | No |
ClinGen TOPMed gnomAD |
|
|
rs755992789 CA320510482 |
238 | M>R | No |
ClinGen Ensembl |
|
|
rs753252691 CA10025584 |
240 | P>R | No |
ClinGen ExAC gnomAD |
|
|
CA409946511 rs1264878812 |
240 | P>S | No |
ClinGen TOPMed |
|
|
CA320510496 rs1024159376 |
243 | R>Q | No |
ClinGen TOPMed gnomAD |
|
|
CA10025585 rs150430243 |
243 | R>W | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs764505333 CA10025586 |
246 | S>F | No |
ClinGen ExAC gnomAD |
|
|
CA10025587 rs138127643 |
247 | V>I | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
rs116698978 CA10025589 |
249 | V>I | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA10025590 rs745969118 |
251 | Y>C | No |
ClinGen ExAC gnomAD |
|
|
CA409946707 rs1471504426 |
255 | S>T | No |
ClinGen gnomAD |
|
|
CA409946737 rs1165873704 |
257 | D>N | No |
ClinGen TOPMed gnomAD |
|
|
rs1388690974 CA409946796 |
261 | S>G | No |
ClinGen gnomAD |
|
|
CA10025592 rs780262985 |
262 | N>S | No |
ClinGen ExAC gnomAD |
|
|
CA10025594 rs768711199 |
264 | N>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA409946886 rs1445946373 |
268 | N>D | No |
ClinGen gnomAD |
|
|
CA10025595 rs776625757 |
270 | S>T | No |
ClinGen ExAC gnomAD |
|
|
CA409947034 rs1365417546 |
271 | G>E | No |
ClinGen gnomAD |
|
|
rs1224272595 CA409947038 |
272 | T>A | No |
ClinGen TOPMed |
|
|
rs747916912 CA10025613 |
272 | T>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs770553759 CA10025617 |
273 | P>L | No |
ClinGen ExAC gnomAD |
|
|
CA10025616 rs749006471 |
273 | P>T | No |
ClinGen ExAC gnomAD |
|
|
CA409947047 rs1465040434 |
274 | K>E | No |
ClinGen gnomAD |
|
|
CA10025619 rs758977569 |
276 | H>R | No |
ClinGen ExAC TOPMed gnomAD |
|
|
COSM3841909 rs777149491 COSM3841910 CA10025621 |
277 | D>N | breast [Cosmic] | No |
ClinGen cosmic curated ExAC TOPMed gnomAD |
|
CA10025622 rs762206299 |
279 | P>L | No |
ClinGen ExAC gnomAD |
|
|
rs750752505 CA10025624 |
282 | G>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs138783369 CA10025625 |
283 | A>V | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA409947160 rs1320107796 |
284 | D>N | No |
ClinGen gnomAD |
|
|
rs755069743 CA10025628 |
287 | E>K | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs755069743 CA409947209 |
287 | E>Q | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA320510900 rs1042607818 |
288 | S>N | No |
ClinGen Ensembl |
|
|
CA409947266 rs1347273131 |
291 | S>T | No |
ClinGen gnomAD |
|
|
rs781109403 CA10025629 |
293 | L>P | No |
ClinGen ExAC gnomAD |
|
|
rs752718830 CA10025630 |
297 | N>T | No |
ClinGen ExAC gnomAD |
|
|
rs146230611 CA10025631 |
299 | Q>P | No |
ClinGen ESP ExAC gnomAD |
|
|
rs1245886108 CA409947404 |
300 | S>L | No |
ClinGen TOPMed |
|
|
CA10025634 rs568367551 |
303 | L>M | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
CA10025636 rs745401875 |
305 | V>M | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs536810041 CA320510916 |
307 | R>Q | No |
ClinGen 1000Genomes gnomAD |
|
|
rs771664787 CA10025637 |
307 | R>W | No |
ClinGen ExAC gnomAD |
|
|
rs1411415689 CA409947949 |
312 | E>K | No |
ClinGen gnomAD |
|
|
CA10025640 rs201065633 |
314 | F>L | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA409947974 rs1365991432 |
315 | E>G | No |
ClinGen TOPMed |
|
|
rs904004816 CA320510920 |
315 | E>K | No |
ClinGen Ensembl |
|
|
rs1274652900 CA409947981 |
316 | D>Y | No |
ClinGen TOPMed |
|
|
CA409947997 rs1323927458 |
318 | C>G | No |
ClinGen TOPMed gnomAD |
|
|
CA409947996 rs1323927458 |
318 | C>R | No |
ClinGen TOPMed gnomAD |
|
|
CA409948000 rs1367378551 |
318 | C>S | No |
ClinGen gnomAD |
|
|
CA10025641 rs773640332 |
319 | S>I | No |
ClinGen ExAC gnomAD |
|
|
rs1407862810 CA409948017 |
320 | Q>H | No |
ClinGen gnomAD |
|
|
CA320510946 rs201705823 |
322 | L>V | No |
ClinGen Ensembl |
|
|
rs1001566013 CA320510948 |
324 | L>F | No |
ClinGen Ensembl |
|
|
rs763343892 CA10025642 |
325 | N>S | No |
ClinGen ExAC gnomAD |
|
|
CA10025643 rs766741634 |
328 | T>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA320510954 rs377345933 |
328 | T>S | No |
ClinGen ESP TOPMed gnomAD |
|
|
rs759798841 CA10025645 |
329 | M>K | No |
ClinGen ExAC gnomAD |
|
|
rs751784308 CA10025644 |
329 | M>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA320510983 rs1028567707 |
332 | K>Q | No |
ClinGen Ensembl |
|
|
CA409948091 rs1412382425 |
332 | K>R | No |
ClinGen TOPMed |
|
|
rs1228112481 CA409948115 |
335 | I>S | No |
ClinGen gnomAD |
|
|
rs767702107 CA10025646 |
338 | R>T | No |
ClinGen ExAC gnomAD |
|
|
CA10025648 rs756087792 |
339 | S>N | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA409948155 rs1451033653 |
340 | D>E | No |
ClinGen TOPMed |
|
|
CA409948152 rs1251221942 |
340 | D>G | No |
ClinGen gnomAD |
|
|
rs139305338 CA10025649 |
341 | P>L | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1472555746 CA409948164 |
342 | V>A | No |
ClinGen gnomAD |
|
|
rs756993602 CA10025651 |
342 | V>M | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs545879938 CA320511001 |
343 | E>Q | No |
ClinGen 1000Genomes |
|
|
CA409948177 rs1466262358 |
344 | Q>R | No |
ClinGen TOPMed gnomAD |
|
|
rs1601431813 CA409948198 |
347 | P>Q | No |
ClinGen Ensembl |
|
|
CA409948215 rs772140972 |
350 | P>S | No |
ClinGen TOPMed gnomAD |
|
|
CA320511006 rs772140972 |
350 | P>T | No |
ClinGen TOPMed gnomAD |
|
|
CA409948219 rs1386846953 |
351 | A>T | No |
ClinGen gnomAD |
|
|
rs116771448 CA10025652 |
353 | V>M | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA409948241 rs1167852113 |
355 | A>T | No |
ClinGen gnomAD |
|
|
CA10025655 rs757163141 |
356 | G>R | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA10025654 rs757163141 |
356 | G>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs746447739 CA10025656 |
358 | T>A | No |
ClinGen ExAC gnomAD |
|
|
CA320511813 rs1040273379 |
359 | G>E | No |
ClinGen TOPMed |
|
|
CA409948264 rs1569025991 |
359 | G>R | No |
ClinGen Ensembl |
|
|
CA409948326 rs1262150746 |
366 | W>L | No |
ClinGen gnomAD |
|
|
CA320511826 rs535614049 |
377 | S>C | No |
ClinGen Ensembl |
|
|
CA409948398 rs1480489542 |
377 | S>P | No |
ClinGen gnomAD |
|
|
rs764200775 CA10025683 |
378 | C>S | No |
ClinGen ExAC gnomAD |
|
|
rs776691299 CA409948415 |
379 | Q>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs761800465 CA10025685 |
382 | I>T | No |
ClinGen ExAC gnomAD |
|
|
CA409948450 rs1465836920 |
384 | W>L | No |
ClinGen gnomAD |
|
|
CA10025688 rs758089939 |
388 | G>E | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs116387099 CA10025687 |
388 | G>R | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
rs1601433127 CA409948485 |
389 | W>* | No |
ClinGen Ensembl |
|
|
CA10025691 rs754652236 |
394 | A>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA409948527 rs1228007843 |
395 | D>E | No |
ClinGen TOPMed gnomAD |
|
|
rs115880316 CA320511859 |
395 | D>N | No |
ClinGen 1000Genomes TOPMed gnomAD |
|
|
CA409948543 rs1601433167 |
398 | E>K | No |
ClinGen Ensembl |
|
|
rs1331422908 CA409948567 |
399 | V>A | No |
ClinGen TOPMed |
|
|
rs1331422908 CA409948568 |
399 | V>G | No |
ClinGen TOPMed |
|
|
rs1601433852 CA409948570 |
400 | A>P | No |
ClinGen Ensembl |
|
|
rs1389242494 CA409948575 COSM1414074 COSM1414075 |
401 | R>C | large_intestine [Cosmic] | No |
ClinGen cosmic curated TOPMed |
|
COSM1251536 COSM1251535 rs1252271782 CA409948578 |
401 | R>H | oesophagus [Cosmic] | No |
ClinGen cosmic curated gnomAD |
|
rs762726949 CA320512273 |
402 | R>Q | No |
ClinGen gnomAD |
|
|
rs1421624560 CA409948582 |
402 | R>W | No |
ClinGen TOPMed gnomAD |
|
|
rs200586471 CA320512276 |
410 | P>L | No |
ClinGen 1000Genomes |
|
|
CA10025712 rs777392517 COSM1534698 COSM1534699 |
411 | K>T | lung [Cosmic] | No |
ClinGen cosmic curated ExAC TOPMed gnomAD |
|
CA320512308 rs914709352 |
426 | D>N | No |
ClinGen TOPMed |
|
|
CA10025719 rs376004538 |
433 | T>M | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA409948808 rs1365534454 |
433 | T>S | No |
ClinGen TOPMed |
|
|
rs769911963 CA10025721 |
434 | S>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1470009589 COSM236734 CA409948832 |
437 | R>C | prostate [Cosmic] | No |
ClinGen cosmic curated TOPMed |
|
COSM176132 CA10025724 rs762854102 |
437 | R>H | large_intestine [Cosmic] | No |
ClinGen cosmic curated ExAC gnomAD |
|
CA409948843 rs1482108080 |
439 | V>M | No |
ClinGen gnomAD |
|
|
CA409948858 rs1180885980 |
441 | R>C | No |
ClinGen gnomAD |
|
|
rs1242969238 CA409948862 |
441 | R>L | No |
ClinGen gnomAD |
|
|
rs558667507 CA320512330 |
443 | V>M | No |
ClinGen 1000Genomes |
|
|
CA409948890 rs1185768997 |
445 | D>E | No |
ClinGen gnomAD |
|
|
rs1310195239 CA409948885 |
445 | D>N | No |
ClinGen gnomAD |
|
|
rs774020003 CA10025726 |
447 | Q>R | No |
ClinGen ExAC gnomAD |
|
|
rs908656630 CA320512352 |
450 | L>M | No |
ClinGen TOPMed |
|
|
CA320512359 rs997447535 |
453 | T>M | No |
ClinGen TOPMed |
|
|
CA10025728 rs767296660 |
454 | P>A | No |
ClinGen ExAC gnomAD |
|
|
rs1601434046 CA409948948 |
455 | E>K | No |
ClinGen Ensembl |
|
|
rs147744979 CA320512366 |
456 | E>K | No |
ClinGen ESP |
|
|
rs753377257 CA409948975 |
458 | H>Q | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA409948976 rs1442441699 |
459 | A>T | No |
ClinGen TOPMed |
|
|
CA409948981 rs1347801283 |
459 | A>V | No |
ClinGen TOPMed |
|
|
CA10025733 rs142665354 |
462 | G>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA10025734 rs766845683 |
463 | V>A | No |
ClinGen ExAC gnomAD |
|
|
CA409948999 rs1361203764 |
463 | V>I | No |
ClinGen gnomAD |
|
|
CA409949010 rs1601434097 |
464 | Q>H | No |
ClinGen Ensembl |
|
|
rs1206754324 CA409949012 |
465 | P>T | No |
ClinGen gnomAD |
|
|
rs1016137301 CA320512405 |
466 | D>E | No |
ClinGen Ensembl |
|
|
CA320512403 rs1005358178 |
466 | D>N | No |
ClinGen TOPMed gnomAD |
|
|
rs1202427968 CA409949022 |
466 | D>V | No |
ClinGen gnomAD |
|
|
CA409949027 rs1263407730 |
467 | T>M | No |
ClinGen gnomAD |
|
|
CA409949038 rs1192553759 |
469 | D>N | No |
ClinGen gnomAD |
|
|
CA409949043 rs1439045774 |
469 | D>V | No |
ClinGen TOPMed |
No associated diseases with P15036
Functions
| Description | ||
|---|---|---|
| EC Number | ||
| Subcellular Localization |
|
|
| PANTHER Family | PTHR11849 | ETS |
| PANTHER Subfamily | PTHR11849:SF188 | PROTEIN C-ETS-2 |
| PANTHER Protein Class |
DNA-binding transcription factor
helix-turn-helix transcription factor winged helix/forkhead transcription factor |
|
| PANTHER Pathway Category | No pathway information available | |
5 GO annotations of cellular component
| Name | Definition |
|---|---|
| chromatin | The ordered and organized complex of DNA, protein, and sometimes RNA, that forms the chromosome. |
| cytosol | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| nucleoplasm | That part of the nuclear content other than the chromosomes or the nucleolus. |
| nucleus | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| plasma membrane | The membrane surrounding a cell that separates the cell from its external environment. It consists of a phospholipid bilayer and associated proteins. |
8 GO annotations of molecular function
| Name | Definition |
|---|---|
| DNA binding | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| DNA-binding transcription factor activity | A transcription regulator activity that modulates transcription of gene sets via selective and non-covalent binding to a specific double-stranded genomic DNA sequence (sometimes referred to as a motif) within a cis-regulatory region. Regulatory regions include promoters (proximal and distal) and enhancers. Genes are transcriptional units, and include bacterial operons. |
| DNA-binding transcription factor activity, RNA polymerase II-specific | A DNA-binding transcription factor activity that modulates the transcription of specific gene sets transcribed by RNA polymerase II. |
| DNA-binding transcription repressor activity, RNA polymerase II-specific | A DNA-binding transcription factor activity that represses or decreases the transcription of specific gene sets transcribed by RNA polymerase II. |
| protein domain specific binding | Binding to a specific domain of a protein. |
| RNA polymerase II cis-regulatory region sequence-specific DNA binding | Binding to a specific upstream regulatory DNA sequence (transcription factor recognition sequence or binding site) located in cis relative to the transcription start site (i.e., on the same strand of DNA) of a gene transcribed by RNA polymerase II. |
| RNA polymerase II-specific DNA-binding transcription factor binding | Binding to a sequence-specific DNA binding RNA polymerase II transcription factor, any of the factors that interact selectively and non-covalently with a specific DNA sequence in order to modulate transcription. |
| sequence-specific double-stranded DNA binding | Binding to double-stranded DNA of a specific nucleotide composition, e.g. GC-rich DNA binding, or with a specific sequence motif or type of DNA, e.g. promotor binding or rDNA binding. |
8 GO annotations of biological process
| Name | Definition |
|---|---|
| cell differentiation | The process in which relatively unspecialized cells, e.g. embryonic or regenerative cells, acquire specialized structural and/or functional features that characterize the cells, tissues, or organs of the mature organism or some other relatively stable phase of the organism's life history. Differentiation includes the processes involved in commitment of a cell to a specific fate and its subsequent development to the mature state. |
| ectodermal cell fate commitment | The cell differentiation process that results in commitment of a cell to become part of the ectoderm. |
| mesoderm development | The process whose specific outcome is the progression of the mesoderm over time, from its formation to the mature structure. The mesoderm is the middle germ layer that develops into muscle, bone, cartilage, blood and connective tissue. |
| negative regulation of transcription by RNA polymerase II | Any process that stops, prevents, or reduces the frequency, rate or extent of transcription mediated by RNA polymerase II. |
| positive regulation of transcription by RNA polymerase II | Any process that activates or increases the frequency, rate or extent of transcription from an RNA polymerase II promoter. |
| primitive streak formation | The developmental process pertaining to the initial formation of the primitive streak from unspecified parts. The primitive streak is a ridge of cells running along the midline of the embryo where the mesoderm ingresses. It defines the anterior-posterior axis. |
| regulation of transcription by RNA polymerase II | Any process that modulates the frequency, rate or extent of transcription mediated by RNA polymerase II. |
| skeletal system development | The process whose specific outcome is the progression of the skeleton over time, from its formation to the mature structure. The skeleton is the bony framework of the body in vertebrates (endoskeleton) or the hard outer envelope of insects (exoskeleton or dermoskeleton). |
40 homologous proteins in AiPD
| UniProt AC | Gene Name | Protein Name | Species | Evidence Code |
|---|---|---|---|---|
| Q2KIC2 | ETV1 | ETS translocation variant 1 | Bos taurus (Bovine) | SS |
| A1A4L6 | ETS2 | Protein C-ets-2 | Bos taurus (Bovine) | SS |
| P15062 | ETS1 | Transforming protein p68/c-ets-1 | Gallus gallus (Chicken) | SS |
| Q90837 | ERG | Transcriptional regulator Erg | Gallus gallus (Chicken) | SS |
| P10157 | ETS2 | Protein C-ets-2 | Gallus gallus (Chicken) | SS |
| A2T762 | ETV3 | ETS translocation variant 3 | Pan troglodytes (Chimpanzee) | PR |
| Q04688 | Ets97D | DNA-binding protein Ets97D | Drosophila melanogaster (Fruit fly) | PR |
| P41970 | ELK3 | ETS domain-containing protein Elk-3 | Homo sapiens (Human) | SS |
| Q06546 | GABPA | GA-binding protein alpha chain | Homo sapiens (Human) | SS |
| Q9Y603 | ETV7 | Transcription factor ETV7 | Homo sapiens (Human) | SS |
| P41212 | ETV6 | Transcription factor ETV6 | Homo sapiens (Human) | SS |
| P78545 | ELF3 | ETS-related transcription factor Elf-3 | Homo sapiens (Human) | SS |
| Q9UKW6 | ELF5 | ETS-related transcription factor Elf-5 | Homo sapiens (Human) | EV |
| P32519 | ELF1 | ETS-related transcription factor Elf-1 | Homo sapiens (Human) | PR |
| Q99607 | ELF4 | ETS-related transcription factor Elf-4 | Homo sapiens (Human) | PR |
| O95238 | SPDEF | SAM pointed domain-containing Ets transcription factor | Homo sapiens (Human) | PR |
| P50548 | ERF | ETS domain-containing transcription factor ERF | Homo sapiens (Human) | PR |
| P41162 | ETV3 | ETS translocation variant 3 | Homo sapiens (Human) | PR |
| P11308 | ERG | Transcriptional regulator ERG | Homo sapiens (Human) | EV |
| P43268 | ETV4 | ETS translocation variant 4 | Homo sapiens (Human) | EV |
| P41161 | ETV5 | ETS translocation variant 5 | Homo sapiens (Human) | SS |
| P50549 | ETV1 | ETS translocation variant 1 | Homo sapiens (Human) | EV |
| P28324 | ELK4 | ETS domain-containing protein Elk-4 | Homo sapiens (Human) | EV |
| P19419 | ELK1 | ETS domain-containing protein Elk-1 | Homo sapiens (Human) | EV |
| P14921 | ETS1 | Protein C-ets-1 | Homo sapiens (Human) | EV |
| P41971 | Elk3 | ETS domain-containing protein Elk-3 | Mus musculus (Mouse) | EV |
| Q00422 | Gabpa | GA-binding protein alpha chain | Mus musculus (Mouse) | EV |
| P41969 | Elk1 | ETS domain-containing protein Elk-1 | Mus musculus (Mouse) | PR |
| P28322 | Etv4 | ETS translocation variant 4 | Mus musculus (Mouse) | SS |
| P27577 | Ets1 | Protein C-ets-1 | Mus musculus (Mouse) | EV |
| P70459 | Erf | ETS domain-containing transcription factor ERF | Mus musculus (Mouse) | PR |
| Q9CXC9 | Etv5 | ETS translocation variant 5 | Mus musculus (Mouse) | SS |
| P41158 | Elk4 | ETS domain-containing protein Elk-4 | Mus musculus (Mouse) | PR |
| P41164 | Etv1 | ETS translocation variant 1 | Mus musculus (Mouse) | SS |
| P81270 | Erg | Transcriptional regulator ERG | Mus musculus (Mouse) | SS |
| P15037 | Ets2 | Protein C-ets-2 | Mus musculus (Mouse) | SS |
| P41156 | Ets1 | Protein C-ets-1 | Rattus norvegicus (Rat) | SS |
| A4GTP4 | Elk1 | ETS domain-containing protein Elk-1 | Rattus norvegicus (Rat) | PR |
| Q9PUQ1 | etv4 | ETS translocation variant 4 | Danio rerio (Zebrafish) (Brachydanio rerio) | SS |
| A3FEM2 | fev | Protein FEV | Danio rerio (Zebrafish) (Brachydanio rerio) | PR |
| 10 | 20 | 30 | 40 | 50 | 60 |
| MNDFGIKNMD | QVAPVANSYR | GTLKRQPAFD | TFDGSLFAVF | PSLNEEQTLQ | EVPTGLDSIS |
| 70 | 80 | 90 | 100 | 110 | 120 |
| HDSANCELPL | LTPCSKAVMS | QALKATFSGF | KKEQRRLGIP | KNPWLWSEQQ | VCQWLLWATN |
| 130 | 140 | 150 | 160 | 170 | 180 |
| EFSLVNVNLQ | RFGMNGQMLC | NLGKERFLEL | APDFVGDILW | EHLEQMIKEN | QEKTEDQYEE |
| 190 | 200 | 210 | 220 | 230 | 240 |
| NSHLTSVPHW | INSNTLGFGT | EQAPYGMQTQ | NYPKGGLLDS | MCPASTPSVL | SSEQEFQMFP |
| 250 | 260 | 270 | 280 | 290 | 300 |
| KSRLSSVSVT | YCSVSQDFPG | SNLNLLTNNS | GTPKDHDSPE | NGADSFESSD | SLLQSWNSQS |
| 310 | 320 | 330 | 340 | 350 | 360 |
| SLLDVQRVPS | FESFEDDCSQ | SLCLNKPTMS | FKDYIQERSD | PVEQGKPVIP | AAVLAGFTGS |
| 370 | 380 | 390 | 400 | 410 | 420 |
| GPIQLWQFLL | ELLSDKSCQS | FISWTGDGWE | FKLADPDEVA | RRWGKRKNKP | KMNYEKLSRG |
| 430 | 440 | 450 | 460 | ||
| LRYYYDKNII | HKTSGKRYVY | RFVCDLQNLL | GFTPEELHAI | LGVQPDTED |