O60264
Gene name |
SMARCA5 (SNF2H, WCRF135) |
Protein name |
SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily A member 5 |
Names |
SWI/SNF-related matrix-associated actin-dependent regulator of chromatin A5, Sucrose nonfermenting protein 2 homolog, hSNF2H |
Species |
Homo sapiens (Human) |
KEGG Pathway |
hsa:8467 |
EC number |
|
Protein Class |
CHROMODOMAIN-HELICASE-DNA-BINDING PROTEIN 3-RELATED-RELATED (PTHR45623) |
Descriptions
SMARCA5 (SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily A member 5, SNF2h) is a helicase that possesses intrinsic ATP-dependent nucleosome-remodeling activity and a catalytic subunit of ISWI chromatin-remodeling complexes, which form ordered nucleosome arrays on chromatin and facilitate access to DNA during DNA-templated processes such as DNA replication, transcription, and repair.
A highly conserved acidic patch formed by histones H2A and H2B of the nucleosome relieves the autoinhibition imposed by the AutoN and the NegC regions of the SMARCA5. In the autoinhibited state, AutoN and NegC hold the remodeler in an inactive state. The active state is promoted by AutoN and NegC binding near the acidic patch and by H4 tail binding to the ATPase domain. Thus, the acidic patch helps promote the translocation competent state of SMARCA5 by providing a binding site for NegC and AutoN.
Autoinhibitory domains (AIDs)
Target domain |
183-638 (Helicase domain) |
Relief mechanism |
Partner binding |
Assay |
Mutagenesis experiment |
Target domain |
183-638 (Helicase domain) |
Relief mechanism |
Partner binding |
Assay |
Mutagenesis experiment |
Accessory elements
No accessory elements
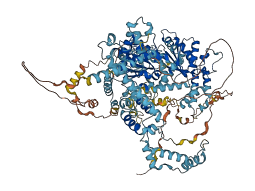
Autoinhibited structure

Activated structure
2 structures for O60264
| Entry ID | Method | Resolution | Chain | Position | Source |
|---|---|---|---|---|---|
| 6NE3 | EM | 390 A | W | 166-634 | PDB |
| AF-O60264-F1 | Predicted | AlphaFoldDB |
392 variants for O60264
| Variant ID(s) | Position | Change | Description | Diseaes Association | Provenance |
|---|---|---|---|---|---|
|
rs763530655 CA3090815 |
2 | S>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA106861309 rs895582831 |
3 | S>F | No |
ClinGen TOPMed gnomAD |
|
|
CA358323791 rs1318633746 |
4 | A>V | No |
ClinGen gnomAD |
|
|
rs926979803 CA106861314 |
5 | A>S | No |
ClinGen gnomAD |
|
|
CA358323812 rs1213203256 |
6 | E>G | No |
ClinGen TOPMed gnomAD |
|
|
CA358323808 rs1346021469 |
6 | E>K | No |
ClinGen gnomAD |
|
|
rs1482965442 CA358323831 |
8 | P>A | No |
ClinGen TOPMed gnomAD |
|
|
CA106861318 rs550742639 |
8 | P>L | No |
ClinGen 1000Genomes |
|
|
rs1175823902 CA358323840 |
9 | P>A | No |
ClinGen TOPMed gnomAD |
|
|
rs1253330066 CA358323844 |
9 | P>L | No |
ClinGen gnomAD |
|
|
CA358323841 rs1175823902 |
9 | P>S | No |
ClinGen TOPMed gnomAD |
|
|
rs1420160625 CA358323850 |
10 | P>S | No |
ClinGen gnomAD |
|
|
CA106861319 rs866864993 |
11 | P>Q | No |
ClinGen gnomAD |
|
|
CA3090817 rs751684290 |
11 | P>S | No |
ClinGen ExAC gnomAD |
|
|
rs767504303 CA3090819 |
12 | P>L | No |
ClinGen ExAC gnomAD |
|
|
CA3090818 rs755161701 |
12 | P>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1578786690 CA358323881 |
13 | P>L | No |
ClinGen Ensembl |
|
|
rs752894762 CA3090820 |
13 | P>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3090821 rs756319010 |
14 | E>K | No |
ClinGen ExAC gnomAD |
|
|
CA3090822 rs568763709 |
15 | S>N | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA3090823 rs745715907 |
16 | A>G | No |
ClinGen ExAC gnomAD |
|
|
rs758303815 CA3090824 |
17 | P>L | No |
ClinGen ExAC gnomAD |
|
|
CA3090825 rs780037066 |
18 | S>C | No |
ClinGen ExAC gnomAD |
|
|
rs746508886 CA3090826 |
19 | K>E | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3090827 CA358323933 rs768156171 |
19 | K>N | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA106861335 rs904221635 |
20 | P>H | No |
ClinGen TOPMed gnomAD |
|
|
CA358323941 rs904221635 |
20 | P>L | No |
ClinGen TOPMed gnomAD |
|
|
CA3090828 rs776010437 |
21 | A>E | No |
ClinGen ExAC gnomAD |
|
|
rs865837289 CA358323943 |
21 | A>P | No |
ClinGen gnomAD |
|
|
CA106861341 rs865837289 |
21 | A>T | No |
ClinGen gnomAD |
|
|
rs999860410 CA358323962 |
22 | A>G | No |
ClinGen TOPMed gnomAD |
|
|
rs1452094027 CA358323956 |
22 | A>S | No |
ClinGen gnomAD |
|
|
rs999860410 CA106861349 |
22 | A>V | No |
ClinGen TOPMed gnomAD |
|
|
CA3090830 rs769379037 |
23 | S>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA106861353 rs769379037 |
23 | S>W | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1168087556 CA358323987 |
24 | I>M | No |
ClinGen gnomAD |
|
|
rs773679966 CA3090831 |
25 | A>P | No |
ClinGen ExAC gnomAD |
|
|
rs1325206930 CA358324025 |
27 | G>S | No |
ClinGen gnomAD |
|
|
rs1265587137 CA358324047 |
28 | G>W | No |
ClinGen TOPMed |
|
|
CA106861359 rs966554565 |
29 | S>G | No |
ClinGen gnomAD |
|
|
rs1364758612 CA358324109 |
31 | S>N | No |
ClinGen gnomAD |
|
|
CA358324148 rs759962281 |
33 | N>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs759962281 CA3090835 |
33 | N>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs767591548 CA3090836 |
34 | K>R | No |
ClinGen ExAC gnomAD |
|
|
CA106861374 rs997581034 |
35 | G>S | No |
ClinGen TOPMed gnomAD |
|
|
rs752744842 CA3090837 |
35 | G>V | No |
ClinGen ExAC gnomAD |
|
|
CA358324189 rs1241458974 |
36 | G>C | No |
ClinGen TOPMed |
|
|
rs750218985 CA3090840 |
36 | G>V | No |
ClinGen ExAC gnomAD |
|
|
rs758248170 CA3090841 |
37 | P>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs779838589 CA3090842 |
38 | E>K | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1421187468 CA358324238 |
40 | V>I | No |
ClinGen gnomAD |
|
|
rs1163902970 CA358324258 |
42 | A>P | No |
ClinGen gnomAD |
|
|
rs1462902570 CA358324297 |
44 | A>E | No |
ClinGen gnomAD |
|
|
rs1468817202 CA358324308 |
45 | V>F | No |
ClinGen TOPMed |
|
|
CA106861397 rs986588765 |
46 | A>G | No |
ClinGen TOPMed |
|
|
CA358324347 rs1428721599 |
47 | S>F | No |
ClinGen gnomAD |
|
|
rs748958303 CA3090849 |
49 | A>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3090851 rs774884127 |
50 | S>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs772507264 CA358324394 |
51 | A>D | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs377525719 CA3090852 |
51 | A>S | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs772507264 CA3090853 |
51 | A>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA106861437 rs867789111 |
53 | P>H | No |
ClinGen Ensembl |
|
|
CA3090854 rs775611324 |
53 | P>S | No |
ClinGen ExAC gnomAD |
|
|
rs760736204 CA358324423 |
54 | A>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs760736204 CA3090855 |
54 | A>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3090856 rs200653868 |
54 | A>V | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA358324454 rs1196323464 |
55 | D>E | No |
ClinGen gnomAD |
|
|
CA358324435 rs1243527828 |
55 | D>Y | No |
ClinGen gnomAD |
|
|
rs754002060 CA3090857 |
56 | A>D | No |
ClinGen ExAC gnomAD |
|
|
CA106861446 rs929530863 |
56 | A>S | No |
ClinGen TOPMed gnomAD |
|
|
rs373857554 CA358324921 |
60 | E>D | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1206455896 CA358324922 CA358324924 |
61 | I>L | No |
ClinGen gnomAD |
|
|
CA358324923 rs1206455896 |
61 | I>V | No |
ClinGen gnomAD |
|
|
CA358324940 rs1233383579 |
63 | D>G | No |
ClinGen TOPMed gnomAD |
|
|
CA358324948 rs751361829 |
64 | D>A | No |
ClinGen ExAC gnomAD |
|
|
CA3090878 rs751361829 |
64 | D>G | No |
ClinGen ExAC gnomAD |
|
|
CA3090879 rs754593322 |
65 | A>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA106862699 rs944364500 |
67 | P>L | No |
ClinGen TOPMed gnomAD |
|
|
CA358324969 rs1417725633 CA358324968 |
68 | G>R | No |
ClinGen gnomAD |
|
|
CA358324975 COSM1051599 rs1411993784 |
69 | K>Q | Variant assessed as Somatic; 0.0 impact. endometrium [NCI-TCGA, Cosmic] | No |
ClinGen cosmic curated NCI-TCGA TOPMed gnomAD |
|
rs1429485916 CA358324978 |
69 | K>R | No |
ClinGen TOPMed |
|
|
CA3090882 rs756150460 |
72 | E>Q | No |
ClinGen ExAC gnomAD |
|
|
rs1185307416 CA358325007 |
73 | I>L | No |
ClinGen TOPMed |
|
|
rs1485561006 CA358325028 |
76 | P>T | No |
ClinGen TOPMed |
|
|
rs763648422 CA3090883 |
78 | P>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs202042006 CA106862705 |
79 | T>A | No |
ClinGen 1000Genomes gnomAD |
|
|
CA358325049 rs1233448620 |
79 | T>N | No |
ClinGen gnomAD |
|
|
CA358325058 rs1216095143 |
80 | Y>* | No |
ClinGen TOPMed gnomAD |
|
|
CA358325054 rs1337284532 |
80 | Y>N | No |
ClinGen gnomAD |
|
|
CA358325060 rs1258674415 |
81 | E>K | No |
ClinGen gnomAD |
|
|
CA358325068 rs1211925844 |
82 | E>K | No |
ClinGen gnomAD |
|
|
rs1578789444 CA358325085 |
84 | M>V | No |
ClinGen Ensembl |
|
|
CA358325409 rs1382351608 |
87 | D>Y | No |
ClinGen gnomAD |
|
|
CA358325417 rs758104763 |
88 | R>L | No |
ClinGen ExAC gnomAD |
|
|
CA3090912 COSM1165422 rs758104763 |
88 | R>Q | large_intestine [Cosmic] | No |
ClinGen cosmic curated ExAC gnomAD |
|
CA3090911 rs749981812 |
88 | R>W | No |
ClinGen ExAC gnomAD |
|
|
rs148302705 CA3090913 |
89 | A>T | No |
ClinGen ESP ExAC gnomAD |
|
| TCGA novel | 90 | N>K | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA106863883 rs112834245 |
92 | F>L | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
rs11100790 CA106863892 |
94 | Y>* | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
rs1168036593 CA358325476 |
97 | K>E | No |
ClinGen TOPMed |
|
| TCGA novel | 98 | Q>R | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 104 | H>R | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs763829215 CA3090917 |
107 | Q>R | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs769692137 CA3090918 |
113 | T>S | No |
ClinGen ExAC gnomAD |
|
|
CA358325596 rs1203782330 |
114 | P>Q | No |
ClinGen TOPMed gnomAD |
|
|
CA358325595 rs1578791865 |
114 | P>S | No |
ClinGen Ensembl |
|
|
CA3090919 rs773372437 |
115 | T>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA358325603 rs1484928787 |
115 | T>I | No |
ClinGen gnomAD |
|
| TCGA novel | 115 | T>S | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA3090921 rs371430907 |
119 | K>R | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA3090922 rs775114490 |
120 | M>I | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen ExAC NCI-TCGA gnomAD |
|
CA358325631 rs1202827831 |
120 | M>V | No |
ClinGen TOPMed |
|
|
CA3090924 rs764115299 |
124 | R>H | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen ExAC NCI-TCGA gnomAD |
|
rs1264166091 CA358325670 |
126 | R>* | No |
ClinGen TOPMed |
|
|
rs1440990938 CA358325671 |
126 | R>Q | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen NCI-TCGA gnomAD |
|
CA3090927 rs761846990 |
127 | I>M | No |
ClinGen ExAC gnomAD |
|
|
rs1213273762 CA358325679 |
127 | I>R | No |
ClinGen gnomAD |
|
| TCGA novel | 130 | D>R | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 134 | N>missing | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs764617010 CA3090928 |
135 | L>* | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA358325742 rs11541117 |
136 | L>I | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA358325743 rs11541117 |
136 | L>V | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA3090932 rs751905457 |
138 | V>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs373191198 CA106863931 |
138 | V>I | No |
ClinGen ESP TOPMed gnomAD |
|
|
COSM1226769 rs751142387 CA3090949 |
144 | R>C | Variant assessed as Somatic; 0.0 impact. large_intestine [NCI-TCGA, Cosmic] | No |
ClinGen cosmic curated ExAC NCI-TCGA gnomAD |
|
rs759214495 CA3090950 COSM3392716 |
144 | R>H | pancreas [Cosmic] | No |
ClinGen cosmic curated ExAC TOPMed gnomAD |
|
CA3090951 rs767821272 |
145 | R>I | No |
ClinGen ExAC gnomAD |
|
|
CA106864768 rs113803949 |
146 | T>A | No |
ClinGen Ensembl |
|
| TCGA novel | 151 | D>N | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 157 | E>A | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA3090955 rs375642827 |
163 | N>S | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
| TCGA novel | 166 | T>I | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 171 | S>C | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
TCGA novel rs139966158 |
173 | S>= | Variant assessed as Somatic; 0.0 impact. Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA3090972 rs761157214 |
174 | Y>C | No |
ClinGen ExAC gnomAD |
|
|
rs1474761534 CA358326815 |
175 | V>A | No |
ClinGen TOPMed gnomAD |
|
|
rs1229571085 CA358326881 |
179 | K>E | No |
ClinGen gnomAD |
|
|
CA358326905 rs1289914448 |
180 | L>Q | No |
ClinGen gnomAD |
|
|
CA358327124 rs1338504487 |
194 | L>S | No |
ClinGen TOPMed |
|
|
CA358327224 rs1488520265 |
200 | N>S | No |
ClinGen gnomAD |
|
|
CA358327243 rs1303961293 |
202 | I>V | No |
ClinGen TOPMed |
|
|
CA106865303 rs945618863 |
217 | S>A | No |
ClinGen gnomAD |
|
|
CA3090992 rs762390754 |
217 | S>C | No |
ClinGen ExAC gnomAD |
|
|
rs1443975572 CA358327856 |
226 | R>G | No |
ClinGen TOPMed gnomAD |
|
|
CA358327916 rs1332734524 |
229 | P>T | No |
ClinGen gnomAD |
|
|
rs766568120 CA3090996 |
233 | M>V | No |
ClinGen ExAC gnomAD |
|
|
CA3090997 rs751762804 |
242 | H>Y | No |
ClinGen ExAC gnomAD |
|
|
rs202032941 CA106865324 |
243 | N>S | No |
ClinGen gnomAD |
|
|
CA358328161 rs1272254887 |
245 | M>T | No |
ClinGen gnomAD |
|
| TCGA novel | 248 | F>L | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA358328339 rs1560814181 |
254 | T>A | No |
ClinGen Ensembl |
|
|
rs1356584427 CA358328423 |
259 | C>G | No |
ClinGen TOPMed gnomAD |
|
|
rs755173346 CA3090998 |
265 | E>G | No |
ClinGen ExAC gnomAD |
|
| TCGA novel | 267 | R>I | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs78019012 CA106865834 |
273 | D>E | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA3091020 rs756987133 |
274 | V>I | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen ExAC NCI-TCGA TOPMed gnomAD |
| TCGA novel | 277 | P>L | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 279 | E>* | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA358329196 rs1208741601 |
279 | E>K | No |
ClinGen TOPMed |
|
| TCGA novel | 284 | V>L | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA358329422 rs1401590635 |
290 | L>I | No |
ClinGen gnomAD |
|
|
rs1313931266 CA358329503 |
296 | V>M | No |
ClinGen TOPMed |
|
| TCGA novel | 300 | F>I | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs1377558148 CA358329587 |
302 | W>C | No |
ClinGen TOPMed |
|
|
CA788367414 rs1314982477 |
304 | Y>* | No |
ClinGen TOPMed |
|
|
CA358329641 rs1391013360 |
308 | D>N | No |
ClinGen TOPMed |
|
|
rs1357325313 CA358329655 |
309 | E>* | No |
ClinGen gnomAD |
|
|
rs1560814874 CA358329712 RCV000736232 |
314 | K>Q | No |
ClinGen ClinVar Ensembl dbSNP |
|
|
CA3091044 rs751069474 |
322 | E>G | No |
ClinGen ExAC gnomAD |
|
|
rs1036450902 CA106866084 |
323 | I>M | No |
ClinGen TOPMed |
|
| TCGA novel | 326 | E>Q | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs754391388 CA3091045 |
331 | N>S | No |
ClinGen ExAC |
|
|
CA358330530 rs1376923682 |
332 | R>K | No |
ClinGen gnomAD |
|
|
CA358330564 rs1402787736 |
334 | L>F | No |
ClinGen gnomAD |
|
|
CA3091050 rs749736992 |
360 | N>D | No |
ClinGen ExAC gnomAD |
|
| TCGA novel | 363 | D>= | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 365 | F>L | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA3091067 rs370390401 |
370 | D>G | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA3091068 rs752292742 |
372 | N>S | No |
ClinGen ExAC gnomAD |
|
|
CA358331272 rs1192719730 |
382 | E>K | No |
ClinGen gnomAD |
|
|
rs867222589 CA106866665 |
385 | H>Y | No |
ClinGen Ensembl |
|
|
rs1425617631 CA358331926 |
389 | R>C | No |
ClinGen gnomAD |
|
| TCGA novel | 391 | F>V | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 395 | R>Q | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs750842047 CA3091091 |
398 | A>T | No |
ClinGen ExAC gnomAD |
|
|
rs758903969 CA3091092 |
399 | D>E | No |
ClinGen ExAC gnomAD |
|
|
rs780599494 CA3091093 |
405 | P>L | No |
ClinGen ExAC gnomAD |
|
|
rs1036973312 CA106868018 |
406 | P>L | No |
ClinGen Ensembl |
|
|
CA3091094 rs747530633 |
406 | P>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3091095 rs569394609 |
410 | V>I | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs370050586 CA3091097 |
414 | V>L | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA358332299 rs1287807324 |
423 | W>L | No |
ClinGen gnomAD |
|
|
rs1223176716 CA358332415 |
427 | I>M | No |
ClinGen TOPMed |
|
|
rs768754123 CA3091123 |
437 | S>L | No |
ClinGen ExAC gnomAD |
|
|
CA106868494 rs895789960 |
440 | K>R | No |
ClinGen TOPMed |
|
|
rs761445300 CA3091125 |
441 | M>V | No |
ClinGen ExAC TOPMed gnomAD |
|
| TCGA novel | 443 | K>R | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 443 | K>T | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs1578799611 CA358332614 |
444 | M>L | No |
ClinGen Ensembl |
|
|
CA358332848 rs1272802796 |
462 | L>V | No |
ClinGen gnomAD |
|
| TCGA novel | 468 | P>T | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA106868501 rs141261120 |
473 | T>S | No |
ClinGen ESP |
|
|
CA106868505 rs751958306 |
476 | M>K | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3091129 rs766684945 |
476 | M>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3091130 rs751958306 |
476 | M>T | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA358333042 rs766684945 |
476 | M>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs755469240 CA3091131 |
480 | T>N | No |
ClinGen ExAC gnomAD |
|
|
rs1343747467 CA358333187 |
484 | K>R | No |
ClinGen TOPMed |
|
|
CA358333214 rs1430653841 |
485 | M>I | No |
ClinGen TOPMed |
|
|
CA358333208 rs1302742256 |
485 | M>T | No |
ClinGen TOPMed |
|
|
rs372160827 CA3091133 |
486 | V>G | No |
ClinGen ESP ExAC gnomAD |
|
|
rs1478552172 CA358333250 |
488 | L>V | No |
ClinGen gnomAD |
|
|
rs749472573 CA3091136 |
494 | K>E | No |
ClinGen ExAC gnomAD |
|
|
rs749472573 CA3091137 |
494 | K>Q | No |
ClinGen ExAC gnomAD |
|
|
rs1168134550 CA358333387 |
497 | E>K | No |
ClinGen TOPMed |
|
|
CA106868526 rs895000690 |
498 | Q>K | No |
ClinGen TOPMed |
|
|
CA3091151 rs756600968 |
499 | G>D | No |
ClinGen ExAC gnomAD |
|
|
CA3091152 rs764211595 |
502 | V>I | No |
ClinGen ExAC TOPMed gnomAD |
|
| TCGA novel | 503 | L>I | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA358334740 rs1401836826 |
506 | S>G | No |
ClinGen gnomAD |
|
|
CA358334865 rs1339995370 |
511 | V>L | No |
ClinGen gnomAD |
|
| TCGA novel | 521 | W>R | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA3091155 rs779337107 |
523 | N>Y | No |
ClinGen ExAC gnomAD |
|
|
rs746108406 CA3091156 |
524 | Y>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs754738040 CA3091157 |
532 | Q>E | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3091158 rs780882749 |
537 | E>G | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA106869221 rs1053724744 |
539 | Q>P | No |
ClinGen Ensembl |
|
|
rs761926840 CA3091175 |
540 | D>G | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen ExAC NCI-TCGA gnomAD |
|
rs140864882 CA106869271 |
543 | N>H | No |
ClinGen ESP |
|
|
rs765414474 CA3091176 |
543 | N>S | No |
ClinGen ExAC gnomAD |
|
|
rs150169073 CA3091178 |
546 | N>S | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA3091179 rs781022174 |
547 | E>G | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA106869281 rs1008228434 |
548 | P>T | No |
ClinGen Ensembl |
|
|
CA358335781 rs1182194082 |
550 | S>G | No |
ClinGen gnomAD |
|
|
CA358335786 rs1377011194 |
550 | S>N | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen NCI-TCGA gnomAD |
|
rs200624886 CA3091180 |
551 | T>A | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs756062246 CA3091181 |
554 | V>I | No |
ClinGen ExAC gnomAD |
|
|
COSM1427321 rs778415632 CA3091185 |
560 | R>C | Variant assessed as Somatic; 0.0 impact. large_intestine [NCI-TCGA, Cosmic] | No |
ClinGen cosmic curated ExAC NCI-TCGA TOPMed gnomAD |
|
rs866583525 CA106869311 |
560 | R>H | Variant assessed as Somatic; impact. [NCI-TCGA] | No |
ClinGen Ensembl NCI-TCGA |
| TCGA novel | 561 | A>T | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA3091188 rs199980668 |
569 | A>G | No |
ClinGen 1000Genomes ExAC |
|
|
CA3091193 rs765362128 |
587 | L>V | No |
ClinGen ExAC gnomAD |
|
|
rs570057557 CA106869324 |
590 | M>V | No |
ClinGen gnomAD |
|
| TCGA novel | 592 | R>Q | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 594 | H>R | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs140508812 CA3091214 |
600 | K>N | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1453790438 CA358336992 |
606 | R>C | No |
ClinGen TOPMed |
|
|
CA106869963 rs868118261 |
606 | R>H | Variant assessed as Somatic; impact. [NCI-TCGA] | No |
ClinGen Ensembl NCI-TCGA |
|
CA358336991 rs1453790438 |
606 | R>S | No |
ClinGen TOPMed |
|
|
rs145660901 CA106869965 |
610 | D>E | No |
ClinGen ESP gnomAD |
|
|
CA3091216 rs763852717 |
613 | V>I | No |
ClinGen ExAC gnomAD |
|
| TCGA novel | 618 | V>A | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA106869975 rs138302916 |
620 | R>H | No |
ClinGen ESP TOPMed |
|
|
rs757181579 CA3091218 |
630 | I>V | No |
ClinGen ExAC gnomAD |
|
| TCGA novel | 632 | I>S | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA358337832 rs1375945961 |
638 | V>M | No |
ClinGen gnomAD |
|
|
rs1560820730 CA358337980 |
644 | K>R | No |
ClinGen Ensembl |
|
| TCGA novel | 658 | A>S | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA106871004 rs1036859981 |
665 | K>R | No |
ClinGen TOPMed |
|
|
CA3091238 rs776397514 |
673 | D>G | No |
ClinGen ExAC gnomAD |
|
|
CA358338598 rs1462708093 |
674 | I>T | No |
ClinGen gnomAD |
|
|
rs1441459311 CA358338622 |
675 | D>N | No |
ClinGen gnomAD |
|
|
CA358338624 rs1441459311 |
675 | D>Y | No |
ClinGen gnomAD |
|
|
rs771507370 CA3091252 |
690 | E>Q | No |
ClinGen ExAC gnomAD |
|
|
CA106871080 rs896091740 |
694 | K>T | No |
ClinGen gnomAD |
|
|
rs1250274907 CA358339089 |
695 | M>V | No |
ClinGen TOPMed |
|
|
rs950245563 CA106871102 |
697 | E>G | No |
ClinGen TOPMed |
|
| TCGA novel | 698 | S>missing | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA358339142 rs1432048812 |
698 | S>I | No |
ClinGen gnomAD |
|
|
rs746005329 CA3091254 |
699 | S>T | No |
ClinGen ExAC gnomAD |
|
|
rs62337403 CA106871115 |
700 | L>F | No |
ClinGen Ensembl |
|
|
CA3091257 rs760919439 |
705 | M>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1354936798 CA358339259 |
707 | T>I | No |
ClinGen TOPMed gnomAD |
|
| TCGA novel | 711 | V>A | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 718 | D>Y | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs762774070 CA3091260 |
721 | E>G | No |
ClinGen ExAC gnomAD |
|
|
CA358339585 rs1457567191 |
725 | I>M | No |
ClinGen TOPMed |
|
|
rs1377236237 CA358339689 |
736 | R>* | No |
ClinGen gnomAD |
|
|
rs373394057 CA106871343 |
741 | N>S | No |
ClinGen ESP |
|
|
rs750888422 CA3091294 |
744 | V>I | No |
ClinGen ExAC gnomAD |
|
|
rs780083407 CA3091296 |
749 | R>T | No |
ClinGen ExAC |
|
| TCGA novel | 756 | E>A | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA358339945 rs1399973117 |
761 | K>R | No |
ClinGen TOPMed |
|
| TCGA novel | 764 | R>P | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 764 | R>Q | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA358341037 rs781165221 |
770 | N>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs781165221 CA3091317 |
770 | N>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3091318 rs748374408 |
774 | F>I | No |
ClinGen ExAC gnomAD |
|
|
rs376869219 CA3091319 |
780 | R>C | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs778840147 CA3091320 |
780 | R>H | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen ExAC NCI-TCGA gnomAD |
|
CA358341724 rs1349639804 |
794 | K>I | No |
ClinGen Ensembl |
|
|
CA358341728 rs1434996654 |
794 | K>N | No |
ClinGen Ensembl |
|
|
CA358341731 rs1328510103 |
795 | T>S | No |
ClinGen TOPMed |
|
|
rs745725913 CA358341753 |
796 | I>F | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs745725913 CA3091321 |
796 | I>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA358341832 rs1307812161 |
798 | Y>S | No |
ClinGen Ensembl |
|
|
rs1350117709 CA358342004 |
800 | V>I | No |
ClinGen TOPMed |
|
| TCGA novel | 802 | R>* | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs749535799 CA3091338 |
802 | R>Q | Variant assessed as Somatic; 0.0 impact. [NCI-TCGA] | No |
ClinGen ExAC NCI-TCGA gnomAD |
|
rs779744282 CA3091340 |
806 | L>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs768522831 CA3091342 |
809 | A>T | No |
ClinGen ExAC gnomAD |
|
|
rs1380892697 CA358342196 |
810 | A>S | No |
ClinGen TOPMed |
|
|
rs1224679790 CA358342222 |
811 | Q>R | No |
ClinGen gnomAD |
|
|
rs1292380011 CA358342251 |
812 | A>S | No |
ClinGen gnomAD |
|
|
CA106871765 rs200569008 |
814 | K>E | No |
ClinGen Ensembl |
|
| TCGA novel | 815 | E>K | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs747720523 CA3091345 |
816 | E>V | No |
ClinGen ExAC gnomAD |
|
|
rs1264124171 CA358342497 |
820 | I>T | No |
ClinGen gnomAD |
|
|
CA106871782 rs1034434626 |
822 | E>A | No |
ClinGen Ensembl |
|
|
CA358342604 rs1346863035 |
824 | E>* | No |
ClinGen TOPMed |
|
| TCGA novel | 830 | E>* | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs769296046 CA3091346 |
830 | E>K | No |
ClinGen ExAC gnomAD |
|
|
rs147351832 CA3091347 |
836 | K>E | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
CA3091358 rs779874652 |
844 | N>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs751368139 CA3091359 |
846 | N>H | No |
ClinGen ExAC gnomAD |
|
| TCGA novel | 848 | R>I | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs754935303 CA3091360 |
848 | R>K | No |
ClinGen ExAC gnomAD |
|
|
rs1346492952 CA358343674 |
854 | I>V | No |
ClinGen gnomAD |
|
|
rs748086851 CA3091362 |
860 | W>C | No |
ClinGen ExAC gnomAD |
|
|
rs371185183 CA3091363 |
862 | R>H | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA3091364 rs777309076 |
865 | I>M | No |
ClinGen ExAC gnomAD |
|
|
CA3091365 rs748920760 |
866 | E>D | No |
ClinGen ExAC gnomAD |
|
|
CA106872032 rs373549412 |
868 | I>V | No |
ClinGen ESP TOPMed |
|
| TCGA novel | 870 | R>K | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs770550176 CA3091366 |
876 | T>I | No |
ClinGen ExAC gnomAD |
|
|
CA358344109 rs1317621520 |
878 | E>D | No |
ClinGen gnomAD |
|
|
rs1235757287 CA358344116 |
879 | E>A | No |
ClinGen gnomAD |
|
|
CA106872040 rs199752848 |
881 | I>V | No |
ClinGen TOPMed gnomAD |
|
|
CA3091381 rs200620340 |
892 | N>S | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA3091383 rs777256031 |
897 | I>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1306149432 CA358344434 |
899 | K>R | No |
ClinGen TOPMed gnomAD |
|
|
rs1181658339 CA358344451 |
901 | M>V | No |
ClinGen TOPMed |
|
| TCGA novel | 905 | E>K | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA3091384 rs748865649 |
909 | A>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1266229653 CA358344607 |
915 | I>K | No |
ClinGen gnomAD |
|
|
CA3091386 rs778373183 |
915 | I>V | No |
ClinGen ExAC gnomAD |
|
|
CA358344638 rs1481121279 |
918 | K>R | No |
ClinGen gnomAD |
|
|
CA106872276 rs1044307374 |
922 | D>Y | No |
ClinGen Ensembl |
|
|
rs1244384514 CA358344684 |
923 | T>S | No |
ClinGen TOPMed |
|
|
CA358344830 rs1161617102 |
925 | I>F | No |
ClinGen gnomAD |
|
|
CA3091407 rs756675906 |
926 | G>R | No |
ClinGen ExAC gnomAD |
|
|
CA358344940 rs1317653396 |
929 | K>R | No |
ClinGen gnomAD |
|
|
CA106872526 rs150903315 |
931 | P>A | No |
ClinGen ESP gnomAD |
|
|
rs1275302109 CA358345134 |
937 | I>V | No |
ClinGen gnomAD |
|
|
rs1433231971 CA358345279 |
942 | N>K | No |
ClinGen gnomAD |
|
|
CA358345316 rs1298564685 |
943 | K>R | No |
ClinGen gnomAD |
|
|
rs745480391 CA3091409 |
946 | N>S | No |
ClinGen ExAC gnomAD |
|
| TCGA novel | 947 | Y>C | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs868515101 CA106872530 |
953 | R>C | No |
ClinGen gnomAD |
|
|
CA106872534 rs913674843 |
958 | M>R | No |
ClinGen TOPMed |
|
| TCGA novel | 960 | H>Y | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs747443665 CA3091412 |
961 | K>R | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA358345927 rs1225068029 |
964 | F>L | No |
ClinGen Ensembl |
|
|
CA3091414 rs777218169 |
968 | N>S | No |
ClinGen ExAC gnomAD |
|
|
CA106872552 rs966859917 |
974 | R>* | Variant assessed as Somatic; impact. [NCI-TCGA] | No |
ClinGen NCI-TCGA TOPMed |
|
CA358346170 rs1444750996 COSM1226770 |
974 | R>Q | Variant assessed as Somatic; 0.0 impact. large_intestine [NCI-TCGA, Cosmic] | No |
ClinGen cosmic curated NCI-TCGA gnomAD |
|
CA358346184 rs1560822162 |
975 | Q>E | No |
ClinGen Ensembl |
|
| TCGA novel | 975 | Q>L | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs748709525 CA3091415 |
976 | C>R | No |
ClinGen ExAC gnomAD |
|
|
rs1248204684 CA358346269 |
979 | N>S | No |
ClinGen gnomAD |
|
|
rs1473115946 CA358346755 |
995 | M>L | No |
ClinGen gnomAD |
|
|
CA358346758 rs1473115946 |
995 | M>V | No |
ClinGen gnomAD |
|
|
CA358311454 rs1448128745 |
996 | E>A | No |
ClinGen TOPMed |
|
| TCGA novel | 999 | R>K | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs370600192 CA106857841 |
1004 | L>I | No |
ClinGen ESP TOPMed |
|
| TCGA novel | 1006 | T>P | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 1007 | L>M | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
| TCGA novel | 1008 | I>K | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs751266785 CA3091431 |
1011 | E>Q | No |
ClinGen ExAC gnomAD |
|
|
CA358311579 rs1391134713 |
1013 | M>I | No |
ClinGen gnomAD |
|
| TCGA novel | 1016 | E>A | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA106857851 rs867963751 |
1020 | K>R | No |
ClinGen Ensembl |
|
| TCGA novel | 1022 | E>D | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
CA358311662 rs1411140068 |
1024 | K>N | No |
ClinGen gnomAD |
|
|
rs1337982374 CA358311659 |
1024 | K>R | No |
ClinGen gnomAD |
|
|
rs144182373 CA106857862 |
1026 | R>Q | No |
ClinGen ESP TOPMed gnomAD |
|
| TCGA novel | 1027 | G>E | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs755343336 CA3091432 |
1028 | P>R | No |
ClinGen ExAC TOPMed gnomAD |
|
| TCGA novel | 1029 | K>E | Variant assessed as Somatic; impact. [NCI-TCGA] | No | NCI-TCGA |
|
rs1560822873 CA358311695 |
1030 | P>A | Variant assessed as Somatic; 4.771e-05 impact. [NCI-TCGA] | No |
ClinGen Ensembl NCI-TCGA |
|
CA106857885 rs868539925 |
1030 | P>L | No |
ClinGen Ensembl |
|
|
rs751213732 CA3091459 |
1035 | R>C | No |
ClinGen ExAC gnomAD |
|
|
CA3091460 rs754714645 |
1035 | R>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA3091461 rs367991075 |
1038 | D>G | No |
ClinGen ESP ExAC gnomAD |
|
|
COSM1427324 rs756443687 CA3091463 |
1040 | A>T | Variant assessed as Somatic; 0.0 impact. large_intestine central_nervous_system [NCI-TCGA, Cosmic] | No |
ClinGen cosmic curated ExAC NCI-TCGA TOPMed gnomAD |
|
rs778287757 CA3091464 |
1040 | A>V | No |
ClinGen ExAC gnomAD |
|
|
rs761915646 CA3091465 |
1041 | P>S | No |
ClinGen ExAC TOPMed gnomAD |
|
|
COSM1051640 rs746068709 CA3091468 |
1044 | R>Q | Variant assessed as Somatic; 0.0 impact. endometrium [NCI-TCGA, Cosmic] | No |
ClinGen cosmic curated ExAC NCI-TCGA gnomAD |
|
CA358311818 rs1388282281 |
1047 | K>R | No |
ClinGen TOPMed |
|
|
rs772337987 CA3091469 COSM285198 |
1048 | K>N | Variant assessed as Somatic; 0.0 impact. large_intestine [NCI-TCGA, Cosmic] | No |
ClinGen cosmic curated ExAC NCI-TCGA gnomAD |
|
rs1435956124 CA358311841 |
1051 | K>Q | No |
ClinGen gnomAD |
No associated diseases with O60264
8 regional properties for O60264
| Type | Name | Position | InterPro Accession |
|---|---|---|---|
| domain | SNF2, N-terminal | 183 - 462 | IPR000330 |
| domain | SANT/Myb domain | 841 - 890 | IPR001005-1 |
| domain | SANT/Myb domain | 943 - 1007 | IPR001005-2 |
| domain | Helicase, C-terminal | 484 - 638 | IPR001650 |
| domain | Helicase superfamily 1/2, ATP-binding domain | 176 - 368 | IPR014001 |
| domain | ISWI, HAND domain | 743 - 841 | IPR015194 |
| domain | SLIDE domain | 898 - 1011 | IPR015195 |
| domain | SANT domain | 840 - 892 | IPR017884 |
Functions
| Description | ||
|---|---|---|
| EC Number | ||
| Subcellular Localization |
|
|
| PANTHER Family | PTHR45623 | CHROMODOMAIN-HELICASE-DNA-BINDING PROTEIN 3-RELATED-RELATED |
| PANTHER Subfamily | PTHR45623:SF49 | SWI_SNF RELATED, MATRIX ASSOCIATED, ACTIN DEPENDENT REGULATOR OF CHROMATIN, SUBFAMILY A, MEMBER 1 |
| PANTHER Protein Class | chromatin/chromatin-binding, or -regulatory protein | |
| PANTHER Pathway Category |
Wnt signaling pathway SWI/SNF |
|
15 GO annotations of cellular component
| Name | Definition |
|---|---|
| ACF complex | An ISWI complex that contains an ATPase subunit of the ISWI family (SNF2H in mammals, Isw2 in S. cerevisiae), an ACF1 homolog, and generally no other subunits, though Xenopus is an exception with a third non-conserved subunit. ACF plays roles in regulation of RNA polymerase II transcription and in DNA replication and repair. |
| B-WICH complex | A chromatin remodeling complex that positively regulates histone H3 acetylation, in particular H3K9, by recruiting histone acetyltransferases to rDNA gene regions. Located in the nucleolus where it assembles on RNA Polymerase I (Pol I) and possibly on RNA Polymerase III (Pol III) promoter and coding regions during early G1 phase and activates the post-initiation phases of Pol I transcription. May also activate RNA Polymerase II (Pol II) gene transcription. In mammals, B-WICH contains the WICH complex core of BAZ1B and SMARCA5, additional protein subunits and possibly rRNAs. Although it contains several catalytic subunits it is not clear which functions are carried out by the complex itself. |
| CHRAC | An ISWI complex that contains an ATPase subunit of the ISWI family (SNF2H in mammals, Isw2 in S. cerevisiae), an ACF1 homolog, and additional small histone fold subunits (generally two of these, but Xenopus has only one and some additional non-conserved subunits). CHRAC plays roles in the regulation of RNA polymerase II transcription and in DNA replication and repair. |
| chromatin silencing complex | Any protein complex that mediates changes in chromatin structure that result in transcriptional silencing. |
| condensed chromosome | A highly compacted molecule of DNA and associated proteins resulting in a cytologically distinct structure. |
| fibrillar center | A structure found most metazoan nucleoli, but not usually found in lower eukaryotes; surrounded by the dense fibrillar component; the zone of transcription from multiple copies of the pre-rRNA genes is in the border region between these two structures. |
| NoRC complex | An ISWI complex that contains an ATPase subunit of the ISWI family (specifically SNF2H in mammals, which contain two ISWI homologs) and a Tip5 homolog. In mammals, NoRC is involved in regulation of transcription from RNAP I and RNA polymerase III promoters. |
| nucleolus | A small, dense body one or more of which are present in the nucleus of eukaryotic cells. It is rich in RNA and protein, is not bounded by a limiting membrane, and is not seen during mitosis. Its prime function is the transcription of the nucleolar DNA into 45S ribosomal-precursor RNA, the processing of this RNA into 5.8S, 18S, and 28S components of ribosomal RNA, and the association of these components with 5S RNA and proteins synthesized outside the nucleolus. This association results in the formation of ribonucleoprotein precursors; these pass into the cytoplasm and mature into the 40S and 60S subunits of the ribosome. |
| nucleoplasm | That part of the nuclear content other than the chromosomes or the nucleolus. |
| nucleus | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| NURF complex | An ISWI complex that contains an ATPase subunit of the ISWI family (SNF2L in mammals), a NURF301 homolog (BPTF in humans), and additional subunits, though the composition of these additional subunits varies slightly with species. NURF is involved in regulation of transcription from TRNA polymerase II promoters. |
| pericentric heterochromatin | Heterochromatin that is located adjacent to the CENP-A rich centromere 'central core' and characterized by methylated H3 histone at lysine 9 (H3K9me2/H3K9me3). |
| RSF complex | An ISWI complex that contains an ATPase subunit of the ISWI family (SNF2H in mammals) and an RSF1 homolog. It mediates nucleosome deposition and generates regularly spaced nucleosome arrays. In mammals, RSF is involved in regulation of transcription from RNA polymerase II promoters). |
| site of double-strand break | A region of a chromosome at which a DNA double-strand break has occurred. DNA damage signaling and repair proteins accumulate at the lesion to respond to the damage and repair the DNA to form a continuous DNA helix. |
| WICH complex | An ISWI complex that contains an ATPase subunit of the ISWI family (specifically SNF2H in mammals, which contain two ISWI homologs) and WSTF (Williams Syndrome Transcription Factor). WICH plays roles in regulation of RNAP I and III transcription and in DNA replication and repair. |
8 GO annotations of molecular function
| Name | Definition |
|---|---|
| ATP binding | Binding to ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| ATP hydrolysis activity | Catalysis of the reaction: ATP + H2O = ADP + H+ phosphate. ATP hydrolysis is used in some reactions as an energy source, for example to catalyze a reaction or drive transport against a concentration gradient. |
| ATP-dependent activity, acting on DNA | Catalytic activity that acts to modify DNA, driven by ATP hydrolysis. |
| ATP-dependent chromatin remodeler activity | An activity, driven by ATP hydrolysis, that modulates the contacts between histones and DNA, resulting in a change in chromosome architecture within the nucleosomal array, leading to chromatin remodeling. |
| DNA binding | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| helicase activity | Catalysis of the reaction: ATP + H2O = ADP + phosphate, to drive the unwinding of a DNA or RNA helix. |
| histone octamer slider activity | A chromatin remodeler activity that slides core histone octamers along chromosomal DNA. |
| nucleosome binding | Binding to a nucleosome, a complex comprised of DNA wound around a multisubunit core and associated proteins, which forms the primary packing unit of DNA into higher order structures. |
20 GO annotations of biological process
| Name | Definition |
|---|---|
| cellular response to leukemia inhibitory factor | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a leukemia inhibitory factor stimulus. |
| chromatin remodeling | A dynamic process of chromatin reorganization resulting in changes to chromatin structure. These changes allow DNA metabolic processes such as transcriptional regulation, DNA recombination, DNA repair, and DNA replication. |
| DNA repair | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| DNA-templated transcription initiation | The initial step of transcription, consisting of the assembly of the RNA polymerase preinitiation complex (PIC) at a gene promoter, as well as the formation of the first few bonds of the RNA transcript. Transcription initiation includes abortive initiation events, which occur when the first few nucleotides are repeatedly synthesized and then released, and ends when promoter clearance takes place. |
| negative regulation of mitotic chromosome condensation | Any process that stops, prevents or reduces the frequency, rate or extent of mitotic chromosome condensation. |
| negative regulation of transcription by RNA polymerase I | Any process that stops, prevents, or reduces the frequency, rate or extent of transcription mediated by RNA polymerase I. |
| nucleosome assembly | The aggregation, arrangement and bonding together of a nucleosome, the beadlike structural units of eukaryotic chromatin composed of histones and DNA. |
| positive regulation of DNA replication | Any process that activates or increases the frequency, rate or extent of DNA replication. |
| positive regulation of histone acetylation | Any process that activates or increases the frequency, rate or extent of the addition of an acetyl group to a histone protein. |
| positive regulation of histone deacetylation | Any process that activates or increases the frequency, rate or extent of the removal of acetyl groups from histones. |
| positive regulation of histone methylation | Any process that activates or increases the frequency, rate or extent of the covalent addition of methyl groups to histones. |
| positive regulation of transcription by RNA polymerase I | Any process that activates or increases the frequency, rate or extent of transcription mediated by RNA polymerase I. |
| positive regulation of transcription by RNA polymerase II | Any process that activates or increases the frequency, rate or extent of transcription from an RNA polymerase II promoter. |
| positive regulation of transcription by RNA polymerase III | Any process that activates or increases the frequency, rate or extent of transcription mediated by RNA polymerase III. |
| rDNA heterochromatin assembly | The formation of heterochromatin at ribosomal DNA, characterized by the modified histone H3K9me3. |
| regulation of DNA methylation | Any process that modulates the frequency, rate or extent of the covalent transfer of a methyl group to either N-6 of adenine or C-5 or N-4 of cytosine. |
| regulation of DNA replication | Any process that modulates the frequency, rate or extent of DNA replication. |
| regulation of DNA-templated transcription | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| regulation of response to DNA damage stimulus | Any process that modulates the frequency, rate or extent of response to DNA damage stimulus. |
| regulation of transcription by RNA polymerase II | Any process that modulates the frequency, rate or extent of transcription mediated by RNA polymerase II. |
17 homologous proteins in AiPD
| UniProt AC | Gene Name | Protein Name | Species | Evidence Code |
|---|---|---|---|---|
| P38144 | ISW1 | ISWI chromatin-remodeling complex ATPase ISW1 | Saccharomyces cerevisiae (strain ATCC 204508 / S288c) (Baker's yeast) | PR |
| Q3B7N1 | CHD1L | Chromodomain-helicase-DNA-binding protein 1-like | Bos taurus (Bovine) | SS |
| Q24368 | Iswi | Chromatin-remodeling complex ATPase chain Iswi | Drosophila melanogaster (Fruit fly) | SS |
| Q86WJ1 | CHD1L | Chromodomain-helicase-DNA-binding protein 1-like | Homo sapiens (Human) | EV |
| Q9NRZ9 | HELLS | Lymphoid-specific helicase | Homo sapiens (Human) | PR |
| Q9H4L7 | SMARCAD1 | SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily A containing DEAD/H box 1 | Homo sapiens (Human) | PR |
| P28370 | SMARCA1 | Probable global transcription activator SNF2L1 | Homo sapiens (Human) | SS |
| Q60848 | Hells | Lymphocyte-specific helicase | Mus musculus (Mouse) | PR |
| Q9CXF7 | Chd1l | Chromodomain-helicase-DNA-binding protein 1-like | Mus musculus (Mouse) | SS |
| Q6PGB8 | Smarca1 | Probable global transcription activator SNF2L1 | Mus musculus (Mouse) | SS |
| Q91ZW3 | Smarca5 | SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily A member 5 | Mus musculus (Mouse) | SS |
| P40201 | Chd1 | Chromodomain-helicase-DNA-binding protein 1 | Mus musculus (Mouse) | PR |
| Q7G8Y3 | Os01g0367900 | Probable chromatin-remodeling complex ATPase chain | Oryza sativa subsp japonica (Rice) | PR |
| P41877 | isw-1 | Chromatin-remodeling complex ATPase chain isw-1 | Caenorhabditis elegans | SS |
| Q22516 | chd-3 | Chromodomain-helicase-DNA-binding protein 3 homolog | Caenorhabditis elegans | PR |
| Q9XFH4 | DDM1 | ATP-dependent DNA helicase DDM1 | Arabidopsis thaliana (Mouse-ear cress) | PR |
| Q8RWY3 | CHR11 | ISWI chromatin-remodeling complex ATPase CHR11 | Arabidopsis thaliana (Mouse-ear cress) | PR |
| 10 | 20 | 30 | 40 | 50 | 60 |
| MSSAAEPPPP | PPPESAPSKP | AASIASGGSN | SSNKGGPEGV | AAQAVASAAS | AGPADAEMEE |
| 70 | 80 | 90 | 100 | 110 | 120 |
| IFDDASPGKQ | KEIQEPDPTY | EEKMQTDRAN | RFEYLLKQTE | LFAHFIQPAA | QKTPTSPLKM |
| 130 | 140 | 150 | 160 | 170 | 180 |
| KPGRPRIKKD | EKQNLLSVGD | YRHRRTEQEE | DEELLTESSK | ATNVCTRFED | SPSYVKWGKL |
| 190 | 200 | 210 | 220 | 230 | 240 |
| RDYQVRGLNW | LISLYENGIN | GILADEMGLG | KTLQTISLLG | YMKHYRNIPG | PHMVLVPKST |
| 250 | 260 | 270 | 280 | 290 | 300 |
| LHNWMSEFKR | WVPTLRSVCL | IGDKEQRAAF | VRDVLLPGEW | DVCVTSYEML | IKEKSVFKKF |
| 310 | 320 | 330 | 340 | 350 | 360 |
| NWRYLVIDEA | HRIKNEKSKL | SEIVREFKTT | NRLLLTGTPL | QNNLHELWSL | LNFLLPDVFN |
| 370 | 380 | 390 | 400 | 410 | 420 |
| SADDFDSWFD | TNNCLGDQKL | VERLHMVLRP | FLLRRIKADV | EKSLPPKKEV | KIYVGLSKMQ |
| 430 | 440 | 450 | 460 | 470 | 480 |
| REWYTRILMK | DIDILNSAGK | MDKMRLLNIL | MQLRKCCNHP | YLFDGAEPGP | PYTTDMHLVT |
| 490 | 500 | 510 | 520 | 530 | 540 |
| NSGKMVVLDK | LLPKLKEQGS | RVLIFSQMTR | VLDILEDYCM | WRNYEYCRLD | GQTPHDERQD |
| 550 | 560 | 570 | 580 | 590 | 600 |
| SINAYNEPNS | TKFVFMLSTR | AGGLGINLAT | ADVVILYDSD | WNPQVDLQAM | DRAHRIGQTK |
| 610 | 620 | 630 | 640 | 650 | 660 |
| TVRVFRFITD | NTVEERIVER | AEMKLRLDSI | VIQQGRLVDQ | NLNKIGKDEM | LQMIRHGATH |
| 670 | 680 | 690 | 700 | 710 | 720 |
| VFASKESEIT | DEDIDGILER | GAKKTAEMNE | KLSKMGESSL | RNFTMDTESS | VYNFEGEDYR |
| 730 | 740 | 750 | 760 | 770 | 780 |
| EKQKIAFTEW | IEPPKRERKA | NYAVDAYFRE | ALRVSEPKAP | KAPRPPKQPN | VQDFQFFPPR |
| 790 | 800 | 810 | 820 | 830 | 840 |
| LFELLEKEIL | FYRKTIGYKV | PRNPELPNAA | QAQKEEQLKI | DEAESLNDEE | LEEKEKLLTQ |
| 850 | 860 | 870 | 880 | 890 | 900 |
| GFTNWNKRDF | NQFIKANEKW | GRDDIENIAR | EVEGKTPEEV | IEYSAVFWER | CNELQDIEKI |
| 910 | 920 | 930 | 940 | 950 | 960 |
| MAQIERGEAR | IQRRISIKKA | LDTKIGRYKA | PFHQLRISYG | TNKGKNYTEE | EDRFLICMLH |
| 970 | 980 | 990 | 1000 | 1010 | 1020 |
| KLGFDKENVY | DELRQCIRNS | PQFRFDWFLK | SRTAMELQRR | CNTLITLIER | ENMELEEKEK |
| 1030 | 1040 | 1050 | |||
| AEKKKRGPKP | STQKRKMDGA | PDGRGRKKKL | KL |