O00505
Gene name |
KPNA3 (QIP2) |
Protein name |
Importin subunit alpha-4 |
Names |
Importin alpha Q2, Qip2, Karyopherin subunit alpha-3, SRP1-gamma |
Species |
Homo sapiens (Human) |
KEGG Pathway |
hsa:3839 |
EC number |
|
Protein Class |
|
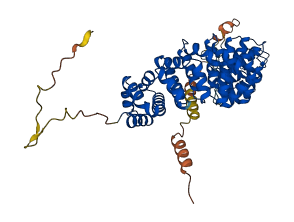
Descriptions
Autoinhibitory domains (AIDs)
Target domain |
103-498 (NLS-binding domain comprising armadillo (Arm) repeats) |
Relief mechanism |
Partner binding |
Assay |
|
Accessory elements
No accessory elements
References
- Kimoto C et al. (2015) "Functional characterization of importin α8 as a classical nuclear localization signal receptor", Biochimica et biophysica acta, 1853, 2676-83
- Kobe B (1999) "Autoinhibition by an internal nuclear localization signal revealed by the crystal structure of mammalian importin alpha", Nature structural biology, 6, 388-97
- Miyatake H et al. (2015) "Crystal structure of human importin-α1 (Rch1), revealing a potential autoinhibition mode involving homodimerization", PloS one, 10, e0115995
- Catimel B et al. (2001) "Biophysical characterization of interactions involving importin-alpha during nuclear import", The Journal of biological chemistry, 276, 34189-98
Autoinhibited structure

Activated structure
1 structures for O00505
| Entry ID | Method | Resolution | Chain | Position | Source |
|---|---|---|---|---|---|
| AF-O00505-F1 | Predicted | AlphaFoldDB |
213 variants for O00505
| Variant ID(s) | Position | Change | Description | Diseaes Association | Provenance |
|---|---|---|---|---|---|
|
CA6983899 rs762963084 |
3 | E>G | No |
ClinGen ExAC gnomAD |
|
|
CA6983898 rs775628381 |
4 | N>S | No |
ClinGen ExAC gnomAD |
|
|
CA6983897 rs769361097 |
5 | P>S | No |
ClinGen ExAC gnomAD |
|
|
rs758980433 CA6983896 |
6 | S>T | No |
ClinGen ExAC gnomAD |
|
|
CA388202063 rs1334115992 |
7 | L>F | No |
ClinGen TOPMed gnomAD |
|
|
CA6983895 rs776297939 |
7 | L>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs867589978 CA249379504 |
8 | E>D | No |
ClinGen Ensembl |
|
|
CA388202058 rs1325149401 |
8 | E>G | No |
ClinGen gnomAD |
|
|
CA6983894 rs770519769 |
8 | E>K | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1387242197 CA388202043 |
10 | H>R | No |
ClinGen gnomAD |
|
|
CA6983892 rs773540519 |
13 | K>R | No |
ClinGen ExAC gnomAD |
|
|
CA6983890 rs748646892 |
17 | N>K | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs779399471 CA249379471 |
18 | K>N | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1451412824 CA388201898 |
19 | G>D | No |
ClinGen gnomAD |
|
|
rs780286546 CA6983886 |
23 | E>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1194431142 CA388201835 |
23 | E>D | No |
ClinGen gnomAD |
|
|
CA388201838 rs780286546 |
23 | E>G | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA388198446 rs1457134228 |
25 | M>T | No |
ClinGen gnomAD |
|
|
rs1302911109 CA388198410 |
30 | N>S | No |
ClinGen TOPMed |
|
|
rs1211666156 CA388197615 |
42 | D>N | No |
ClinGen gnomAD |
|
|
rs780052172 CA6983837 |
43 | E>K | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1281537974 CA388197545 |
51 | V>I | No |
ClinGen Ensembl |
|
|
rs907317489 CA249382049 |
57 | L>V | No |
ClinGen Ensembl |
|
|
CA388197496 rs1365951160 |
58 | E>G | No |
ClinGen gnomAD |
|
|
CA6983832 rs10450846 |
58 | E>K | No |
ClinGen ExAC |
|
|
rs751788282 CA249382043 |
60 | S>A | No |
ClinGen TOPMed |
|
|
rs1323172642 CA388197480 |
60 | S>L | No |
ClinGen gnomAD |
|
|
rs10450845 CA249382042 |
61 | D>N | No |
ClinGen Ensembl |
|
|
rs1434877177 CA388197454 |
64 | A>G | No |
ClinGen gnomAD |
|
|
rs1349712682 CA388197432 |
67 | K>R | No |
ClinGen gnomAD |
|
|
rs957243635 CA249381846 |
69 | Q>R | No |
ClinGen TOPMed |
|
|
rs1471491627 CA388197389 |
70 | N>S | No |
ClinGen gnomAD |
|
|
rs1338338105 CA388197360 |
72 | T>N | No |
ClinGen TOPMed |
|
|
CA249381838 rs10450844 |
74 | E>K | No |
ClinGen ExAC gnomAD |
|
|
CA6983812 rs10450844 |
74 | E>Q | No |
ClinGen ExAC gnomAD |
|
|
rs1181926174 CA388197333 |
75 | A>T | No |
ClinGen gnomAD |
|
|
rs1436706898 CA388197227 |
79 | N>K | No |
ClinGen TOPMed |
|
|
rs1361977200 CA388197231 |
79 | N>S | No |
ClinGen gnomAD |
|
|
CA6983793 rs748362913 |
81 | T>A | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs921469759 CA249381761 |
83 | D>A | No |
ClinGen Ensembl |
|
|
CA388197146 rs1222316990 |
85 | P>L | No |
ClinGen TOPMed |
|
|
rs1566343115 CA388197082 |
90 | S>N | No |
ClinGen Ensembl |
|
|
CA6983789 rs558605678 |
95 | A>T | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
CA249381601 rs536858890 |
109 | D>N | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA6983768 rs536858890 |
109 | D>Y | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1363741876 CA388196763 |
111 | I>L | No |
ClinGen TOPMed gnomAD |
|
|
rs757908201 CA6983766 |
116 | L>S | No |
ClinGen ExAC gnomAD |
|
|
rs1388366106 CA388196689 |
117 | P>S | No |
ClinGen gnomAD |
|
|
rs747735726 CA6983765 |
118 | I>V | No |
ClinGen ExAC |
|
|
CA388196637 rs1362136349 |
121 | K>N | No |
ClinGen Ensembl |
|
|
CA6983763 rs34024081 |
121 | K>R | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
rs34024081 CA388196642 |
121 | K>T | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
rs754283691 CA6983762 |
122 | C>Y | No |
ClinGen ExAC |
|
|
rs756623016 CA6983760 |
125 | R>G | No |
ClinGen ExAC gnomAD |
|
|
rs750807231 CA249381576 |
126 | D>E | No |
ClinGen TOPMed gnomAD |
|
|
CA388196556 rs750951118 |
127 | D>N | No |
ClinGen ExAC gnomAD |
|
|
rs750951118 CA6983759 |
127 | D>Y | No |
ClinGen ExAC gnomAD |
|
|
CA6983757 rs1165237949 |
128 | N>H | No |
ClinGen TOPMed |
|
|
CA919269096 rs1594437515 |
128 | N>K | No |
ClinGen Ensembl |
|
|
rs1271435377 CA388195651 |
129 | P>S | No |
ClinGen gnomAD |
|
|
rs1350942003 CA388195612 |
131 | L>V | No |
ClinGen gnomAD |
|
|
rs878936287 CA249377856 |
142 | I>V | No |
ClinGen Ensembl |
|
|
CA6983729 rs766127523 |
148 | A>V | No |
ClinGen ExAC gnomAD |
|
|
CA6983728 rs760399906 |
151 | Q>E | No |
ClinGen ExAC gnomAD |
|
|
CA249377843 rs17855583 |
152 | A>D | No |
ClinGen TOPMed |
|
|
CA388195034 rs17855583 |
152 | A>V | No |
ClinGen TOPMed |
|
|
CA249377838 rs17855584 |
153 | V>I | No |
ClinGen Ensembl |
|
|
CA6983727 rs567901349 |
156 | S>C | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
CA6983726 rs567901349 |
156 | S>F | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
CA388193937 rs1392120808 |
159 | V>I | No |
ClinGen TOPMed |
|
|
rs374294300 CA249376068 |
160 | P>L | No |
ClinGen ESP TOPMed |
|
|
rs1236399656 CA388193853 |
163 | L>P | No |
ClinGen TOPMed |
|
|
rs1278538848 CA388193829 |
165 | L>I | No |
ClinGen TOPMed |
|
|
rs1159965706 COSM1706781 CA388193795 |
167 | R>C | skin [Cosmic] | No |
ClinGen cosmic curated gnomAD |
|
rs1471595203 CA388193793 |
167 | R>H | No |
ClinGen TOPMed gnomAD |
|
|
rs1471595203 CA388193791 |
167 | R>L | No |
ClinGen TOPMed gnomAD |
|
|
CA388193779 rs1367427471 |
169 | P>S | No |
ClinGen gnomAD |
|
|
rs771348895 CA6983697 |
172 | N>D | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs771348895 CA388193743 |
172 | N>H | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1045600035 CA249376060 |
173 | V>A | No |
ClinGen Ensembl |
|
|
rs1290800128 CA388193727 |
173 | V>I | No |
ClinGen gnomAD |
|
|
CA388193690 rs1253063854 |
176 | Q>* | No |
ClinGen TOPMed |
|
|
rs771224261 CA6983677 |
190 | Q>P | No |
ClinGen ExAC gnomAD |
|
|
CA249375801 rs112989840 |
196 | I>T | No |
ClinGen Ensembl |
|
|
rs1228367748 CA388193381 |
200 | V>A | No |
ClinGen gnomAD |
|
|
CA249375796 rs1045213942 |
202 | K>R | No |
ClinGen TOPMed gnomAD |
|
|
rs1326039478 CA388193348 |
204 | L>V | No |
ClinGen TOPMed |
|
|
CA388193294 rs1434765291 |
209 | S>N | No |
ClinGen gnomAD |
|
|
CA388193244 rs1439407579 |
214 | I>V | No |
ClinGen TOPMed |
|
|
rs1368209197 CA388193234 |
215 | T>A | No |
ClinGen gnomAD |
|
|
rs768849258 CA6983671 |
215 | T>I | No |
ClinGen ExAC gnomAD |
|
|
rs1368209197 CA388193232 |
215 | T>P | No |
ClinGen gnomAD |
|
|
rs930596500 CA249375764 |
217 | L>V | No |
ClinGen Ensembl |
|
|
rs1421586817 COSM1322854 CA388193198 |
218 | R>Q | ovary [Cosmic] | No |
ClinGen cosmic curated gnomAD |
|
CA249375760 rs948854845 |
220 | V>I | No |
ClinGen TOPMed |
|
|
CA388193143 rs1189332677 |
223 | V>A | No |
ClinGen gnomAD |
|
|
rs780438441 CA6983669 |
224 | I>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA388192841 rs1305066063 |
227 | L>F | No |
ClinGen TOPMed |
|
|
rs202115978 CA249375749 |
232 | D>E | No |
ClinGen TOPMed gnomAD |
|
|
rs1263437346 CA388192617 |
234 | P>T | No |
ClinGen TOPMed gnomAD |
|
|
CA388192592 rs1275755303 |
235 | P>A | No |
ClinGen gnomAD |
|
|
CA388192581 rs1217923463 |
235 | P>L | No |
ClinGen gnomAD |
|
|
rs1284291647 CA388192495 |
237 | M>T | No |
ClinGen gnomAD |
|
|
rs1406461612 CA388192445 |
239 | T>I | No |
ClinGen TOPMed gnomAD |
|
|
CA388192413 rs1348224162 |
241 | Q>K | No |
ClinGen gnomAD |
|
|
CA6983642 rs778927656 |
247 | L>V | No |
ClinGen ExAC gnomAD |
|
|
rs1566337293 CA388201952 |
248 | C>Y | No |
ClinGen Ensembl |
|
|
rs753314773 CA6983640 |
250 | L>F | No |
ClinGen ExAC gnomAD |
|
|
CA388201872 rs1244296506 |
256 | I>T | No |
ClinGen TOPMed gnomAD |
|
|
rs765921453 CA6983639 |
256 | I>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs778612372 CA6983623 |
260 | V>A | No |
ClinGen ExAC gnomAD |
|
|
rs1414694114 CA388201753 |
268 | Y>C | No |
ClinGen TOPMed |
|
|
CA6983621 rs749279440 |
274 | N>S | No |
ClinGen ExAC gnomAD |
|
|
CA388201692 rs1452521916 |
277 | I>V | No |
ClinGen TOPMed |
|
|
CA388201671 rs1321875567 |
279 | M>I | No |
ClinGen TOPMed |
|
|
rs374261701 CA6983618 |
283 | S>A | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA388201631 rs1265675572 |
286 | V>M | No |
ClinGen TOPMed gnomAD |
|
|
CA249401412 rs1043015 VAR_014454 |
291 | P>S | No |
ClinGen UniProt TOPMed dbSNP |
|
|
rs1470525099 CA388201505 |
302 | T>I | No |
ClinGen gnomAD |
|
|
CA388201496 rs1224312802 |
304 | A>S | No |
ClinGen TOPMed |
|
|
rs916301724 CA249400282 |
305 | L>P | No |
ClinGen TOPMed |
|
|
CA388201470 rs1469077169 |
308 | V>A | No |
ClinGen TOPMed |
|
|
CA6983599 rs745414229 |
316 | D>N | No |
ClinGen ExAC gnomAD |
|
|
rs1421486079 CA388201385 |
321 | V>L | No |
ClinGen gnomAD |
|
|
CA6983596 rs751231267 |
324 | N>S | No |
ClinGen ExAC |
|
|
CA249400261 rs867554821 |
329 | S>L | No |
ClinGen Ensembl |
|
|
CA6983595 rs764518335 |
331 | F>L | No |
ClinGen ExAC gnomAD |
|
|
rs770745525 CA249400253 |
332 | P>A | No |
ClinGen Ensembl |
|
|
rs17853391 CA249400250 |
332 | P>Q | No |
ClinGen Ensembl |
|
|
COSM947904 rs1566333266 CA388201300 |
334 | L>F | endometrium [Cosmic] | No |
ClinGen cosmic curated Ensembl |
|
CA388201289 rs1566333261 |
336 | S>T | No |
ClinGen Ensembl |
|
|
CA249400229 rs564882588 |
343 | N>S | No |
ClinGen 1000Genomes |
|
|
rs755526497 CA6983573 |
361 | V>I | No |
ClinGen ExAC gnomAD |
|
|
rs754370752 CA6983572 |
363 | A>V | No |
ClinGen ExAC gnomAD |
|
|
CA388201055 rs1338735599 |
367 | A>G | No |
ClinGen gnomAD |
|
|
CA388201022 rs1327046102 |
372 | M>I | No |
ClinGen TOPMed |
|
|
CA6983571 rs184001441 |
372 | M>L | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
CA388201023 rs1381973441 |
372 | M>R | No |
ClinGen TOPMed |
|
|
CA6983569 rs750609683 |
373 | I>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs750609683 CA6983570 |
373 | I>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
CA6983567 rs762064071 |
375 | H>L | No |
ClinGen ExAC gnomAD |
|
|
rs1428869155 CA388200941 |
382 | F>C | No |
ClinGen gnomAD |
|
|
CA249397878 rs878886058 |
387 | E>G | No |
ClinGen Ensembl |
|
|
CA388200899 rs1200363113 |
388 | A>G | No |
ClinGen gnomAD |
|
|
CA388200870 rs1204494087 |
392 | I>M | No |
ClinGen gnomAD |
|
|
CA388200875 rs1182508366 |
392 | I>V | No |
ClinGen gnomAD |
|
|
rs1439172535 CA388200866 |
393 | S>N | No |
ClinGen TOPMed |
|
|
rs1325412646 CA388200863 |
393 | S>R | No |
ClinGen TOPMed |
|
|
rs1438882290 CA388200839 |
397 | I>V | No |
ClinGen gnomAD |
|
|
CA388200817 rs1594428029 |
400 | R>K | No |
ClinGen Ensembl |
|
|
CA388200776 rs1209949995 |
404 | V>I | No |
ClinGen TOPMed |
|
|
CA249397607 rs979380995 |
405 | E>D | No |
ClinGen gnomAD |
|
|
CA249397593 rs17853390 |
411 | N>D | No |
ClinGen Ensembl |
|
|
rs758682416 CA6983525 |
418 | N>K | No |
ClinGen ExAC gnomAD |
|
|
CA388200677 rs1185176995 |
418 | N>Y | No |
ClinGen TOPMed |
|
|
CA249397557 rs923844119 |
422 | V>A | No |
ClinGen Ensembl |
|
|
rs923844119 CA249397553 |
422 | V>G | No |
ClinGen Ensembl |
|
|
CA6983524 rs150806977 |
422 | V>L | No |
ClinGen 1000Genomes ESP ExAC TOPMed gnomAD |
|
|
CA388200622 rs1158602481 |
426 | Q>H | No |
ClinGen gnomAD |
|
|
rs1594427813 CA388200526 |
441 | M>T | No |
ClinGen Ensembl |
|
|
rs1454910799 CA388200516 |
442 | A>V | No |
ClinGen TOPMed |
|
|
rs141253451 CA6983522 |
443 | G>S | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
CA249397541 rs866925883 |
447 | S>G | No |
ClinGen Ensembl |
|
|
rs773285455 CA388200486 |
447 | S>N | No |
ClinGen ExAC gnomAD |
|
|
rs773285455 CA6983521 |
447 | S>T | No |
ClinGen ExAC gnomAD |
|
|
rs1183979163 CA388200473 |
449 | I>T | No |
ClinGen gnomAD |
|
|
rs369254638 CA6983520 |
449 | I>V | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
COSM147689 CA6983518 rs200666130 |
451 | E>D | stomach [Cosmic] | No |
ClinGen cosmic curated 1000Genomes ExAC TOPMed gnomAD |
|
rs553205303 CA6983517 |
452 | I>V | No |
ClinGen 1000Genomes ExAC gnomAD |
|
|
rs1288924141 CA388200446 |
453 | I>M | No |
ClinGen gnomAD |
|
|
rs79884028 CA6983516 |
453 | I>V | No |
ClinGen 1000Genomes ExAC TOPMed gnomAD |
|
|
rs912792431 CA249397503 |
454 | E>D | No |
ClinGen TOPMed |
|
|
CA388200427 rs1234655238 |
456 | C>Y | No |
ClinGen TOPMed |
|
|
CA249395334 rs971159929 |
458 | G>D | No |
ClinGen Ensembl |
|
|
CA6983496 rs763719209 |
461 | K>N | No |
ClinGen ExAC gnomAD |
|
|
CA6983495 rs762510837 |
462 | I>T | No |
ClinGen ExAC gnomAD |
|
|
CA388200332 rs1225080864 |
468 | H>Y | No |
ClinGen gnomAD |
|
|
CA6983494 rs61750351 |
470 | N>S | No |
ClinGen ExAC gnomAD |
|
|
rs1594425920 CA388200303 |
472 | D>N | No |
ClinGen Ensembl |
|
|
CA6983493 rs769999851 |
473 | I>L | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs769999851 CA388200294 |
473 | I>V | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1404435425 CA388200285 |
474 | Y>C | No |
ClinGen gnomAD |
|
|
CA388200252 rs1295841859 |
479 | E>K | No |
ClinGen gnomAD |
|
|
CA249395298 rs1024486447 |
481 | I>M | No |
ClinGen gnomAD |
|
|
CA388200222 rs1289298016 |
483 | Q>E | No |
ClinGen gnomAD |
|
|
CA249395297 rs1013059900 |
483 | Q>H | No |
ClinGen Ensembl |
|
|
CA6983490 rs148675861 |
488 | D>A | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1188185296 CA388200186 |
488 | D>N | No |
ClinGen TOPMed |
|
|
CA6983489 rs747569703 |
489 | D>E | No |
ClinGen ExAC gnomAD |
|
|
rs759231150 CA6983473 |
491 | D>G | No |
ClinGen ExAC gnomAD |
|
|
CA6983474 rs759231150 |
491 | D>V | No |
ClinGen ExAC gnomAD |
|
|
CA388200148 rs1417942947 |
492 | E>K | No |
ClinGen gnomAD |
|
|
rs776963664 CA6983472 |
493 | D>V | No |
ClinGen ExAC gnomAD |
|
|
CA388200134 rs1566329545 |
494 | P>T | No |
ClinGen Ensembl |
|
|
rs1200412156 CA388200123 |
495 | C>F | No |
ClinGen gnomAD |
|
|
CA388200128 rs1348916614 |
495 | C>R | No |
ClinGen TOPMed gnomAD |
|
|
CA6983470 rs761101228 |
497 | I>V | No |
ClinGen ExAC gnomAD |
|
|
rs1345968213 CA388200103 |
498 | P>L | No |
ClinGen TOPMed gnomAD |
|
|
rs1345968213 CA388200104 |
498 | P>R | No |
ClinGen TOPMed gnomAD |
|
|
CA388200108 rs1203335315 |
498 | P>T | No |
ClinGen gnomAD |
|
|
rs893918448 CA249395019 |
499 | E>K | No |
ClinGen Ensembl |
|
|
CA388200070 rs1236984146 |
503 | G>E | No |
ClinGen gnomAD |
|
|
CA249394989 rs771402129 |
504 | G>S | No |
ClinGen Ensembl |
|
|
rs377267111 CA6983468 |
504 | G>V | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1310685327 CA388200061 |
505 | T>S | No |
ClinGen gnomAD |
|
|
CA6983466 rs778898655 |
511 | T>I | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs778898655 CA388200018 |
511 | T>K | No |
ClinGen ExAC TOPMed gnomAD |
|
|
rs1403925715 CA388200004 |
513 | N>K | No |
ClinGen TOPMed gnomAD |
|
|
rs1403925715 CA388200003 |
513 | N>K | No |
ClinGen TOPMed gnomAD |
|
|
rs1401563616 CA388200006 |
513 | N>S | No |
ClinGen TOPMed |
|
|
CA6983464 rs143531983 |
515 | Q>R | No |
ClinGen ESP ExAC TOPMed gnomAD |
|
|
rs1363839479 CA388199966 |
519 | F>L | No |
ClinGen gnomAD |
|
|
CA6983461 rs751398841 |
520 | N>K | No |
ClinGen ExAC gnomAD |
No associated diseases with O00505
6 GO annotations of cellular component
| Name | Definition |
|---|---|
| cytosol | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| host cell | A cell within a host organism. Includes the host plasma membrane and any external encapsulating structures such as the host cell wall and cell envelope. |
| NLS-dependent protein nuclear import complex | A dimer consisting of an alpha and a beta-subunit that imports proteins with an NLS into the nucleus through a nuclear pore. |
| nuclear pore | A protein complex providing a discrete opening in the nuclear envelope of a eukaryotic cell, where the inner and outer nuclear membranes are joined. |
| nucleoplasm | That part of the nuclear content other than the chromosomes or the nucleolus. |
| nucleus | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
3 GO annotations of molecular function
| Name | Definition |
|---|---|
| nuclear import signal receptor activity | Combining with a nuclear import signal (NIS) on a cargo to be transported, to mediate transport of the cargo through the nuclear pore, from the cytoplasm to the nuclear lumen. The cargo can be either a RNA or a protein. |
| nuclear localization sequence binding | Binding to a nuclear localization sequence, a specific peptide sequence that acts as a signal to localize the protein within the nucleus. |
| protein C-terminus binding | Binding to a protein C-terminus, the end of a peptide chain at which the 1-carboxyl function of a constituent amino acid is not attached in peptide linkage to another amino-acid residue. |
4 GO annotations of biological process
| Name | Definition |
|---|---|
| NLS-bearing protein import into nucleus | The directed movement of a protein bearing a nuclear localization signal (NLS) from the cytoplasm into the nucleus, across the nuclear envelope. |
| protein-containing complex assembly | The aggregation, arrangement and bonding together of a set of macromolecules to form a protein-containing complex. |
| viral entry into host cell | The process that occurs after viral attachment by which a virus, or viral nucleic acid, breaches the plasma membrane or cell envelope and enters the host cell. The process ends when the viral nucleic acid is released into the host cell cytoplasm. |
| viral penetration into host nucleus | The crossing by the virus of the host nuclear membrane, either as naked viral genome or for small viruses as an intact capsid. |
30 homologous proteins in AiPD
| UniProt AC | Gene Name | Protein Name | Species | Evidence Code |
|---|---|---|---|---|
| Q02821 | SRP1 | Importin subunit alpha | Saccharomyces cerevisiae (strain ATCC 204508 / S288c) (Baker's yeast) | SS |
| Q0V7M0 | KPNA6 | Importin subunit alpha-7 | Bos taurus (Bovine) | SS |
| A2VE08 | KPNA1 | Importin subunit alpha-5 | Bos taurus (Bovine) | SS |
| C1JZ66 | KPNA7 | Importin subunit alpha-8 | Bos taurus (Bovine) | PR |
| Q5ZML1 | KPNA1 | Importin subunit alpha-5 | Gallus gallus (Chicken) | SS |
| P52295 | Pen | Importin subunit alpha | Drosophila melanogaster (Fruit fly) | SS |
| A9QM74 | KPNA7 | Importin subunit alpha-8 | Homo sapiens (Human) | EV |
| O00629 | KPNA4 | Importin subunit alpha-3 | Homo sapiens (Human) | SS |
| O15131 | KPNA5 | Importin subunit alpha-6 | Homo sapiens (Human) | SS |
| O60684 | KPNA6 | Importin subunit alpha-7 | Homo sapiens (Human) | SS |
| P52292 | KPNA2 | Importin subunit alpha-1 | Homo sapiens (Human) | EV |
| P52294 | KPNA1 | Importin subunit alpha-5 | Homo sapiens (Human) | SS |
| Q60960 | Kpna1 | Importin subunit alpha-5 | Mus musculus (Mouse) | SS |
| O35343 | Kpna4 | Importin subunit alpha-3 | Mus musculus (Mouse) | SS |
| O35345 | Kpna6 | Importin subunit alpha-7 | Mus musculus (Mouse) | PR |
| C0LLJ0 | Kpna7 | Importin subunit alpha-8 | Mus musculus (Mouse) | SS |
| P52293 | Kpna2 | Importin subunit alpha-1 | Mus musculus (Mouse) | EV |
| O35344 | Kpna3 | Importin subunit alpha-4 | Mus musculus (Mouse) | SS |
| C6K7I2 | KPNA7 | Importin subunit alpha-8 | Sus scrofa (Pig) | SS |
| P83953 | Kpna1 | Importin subunit alpha-5 | Rattus norvegicus (Rat) | SS |
| Q56R16 | Kpna5 | Importin subunit alpha-6 | Rattus norvegicus (Rat) | SS |
| Q71VM4 | Os01g0253300 | Importin subunit alpha-1a | Oryza sativa subsp. japonica (Rice) | SS |
| P91276 | ima-2 | Importin subunit alpha-2 | Caenorhabditis elegans | SS |
| Q19969 | ima-3 | Importin subunit alpha-3 | Caenorhabditis elegans | SS |
| O04294 | IMPA3 | Importin subunit alpha-3 | Arabidopsis thaliana (Mouse-ear cress) | SS |
| Q9FJ09 | IMPA5 | Importin subunit alpha-5 | Arabidopsis thaliana (Mouse-ear cress) | SS |
| Q9M9X7 | IMPA7 | Importin subunit alpha-7 | Arabidopsis thaliana (Mouse-ear cress) | SS |
| Q9FWY7 | IMPA6 | Importin subunit alpha-6 | Arabidopsis thaliana (Mouse-ear cress) | SS |
| O22478 | Importin subunit alpha | Solanum lycopersicum (Tomato) (Lycopersicon esculentum) | SS | |
| Q503E9 | kpna5 | Importin subunit alpha-6 | Danio rerio (Zebrafish) (Brachydanio rerio) | SS |
| 10 | 20 | 30 | 40 | 50 | 60 |
| MAENPSLENH | RIKSFKNKGR | DVETMRRHRN | EVTVELRKNK | RDEHLLKKRN | VPQEESLEDS |
| 70 | 80 | 90 | 100 | 110 | 120 |
| DVDADFKAQN | VTLEAILQNA | TSDNPVVQLS | AVQAARKLLS | SDRNPPIDDL | IKSGILPILV |
| 130 | 140 | 150 | 160 | 170 | 180 |
| KCLERDDNPS | LQFEAAWALT | NIASGTSAQT | QAVVQSNAVP | LFLRLLRSPH | QNVCEQAVWA |
| 190 | 200 | 210 | 220 | 230 | 240 |
| LGNIIGDGPQ | CRDYVISLGV | VKPLLSFISP | SIPITFLRNV | TWVIVNLCRN | KDPPPPMETV |
| 250 | 260 | 270 | 280 | 290 | 300 |
| QEILPALCVL | IYHTDINILV | DTVWALSYLT | DGGNEQIQMV | IDSGVVPFLV | PLLSHQEVKV |
| 310 | 320 | 330 | 340 | 350 | 360 |
| QTAALRAVGN | IVTGTDEQTQ | VVLNCDVLSH | FPNLLSHPKE | KINKEAVWFL | SNITAGNQQQ |
| 370 | 380 | 390 | 400 | 410 | 420 |
| VQAVIDAGLI | PMIIHQLAKG | DFGTQKEAAW | AISNLTISGR | KDQVEYLVQQ | NVIPPFCNLL |
| 430 | 440 | 450 | 460 | 470 | 480 |
| SVKDSQVVQV | VLDGLKNILI | MAGDEASTIA | EIIEECGGLE | KIEVLQQHEN | EDIYKLAFEI |
| 490 | 500 | 510 | 520 | ||
| IDQYFSGDDI | DEDPCLIPEA | TQGGTYNFDP | TANLQTKEFN | F |